이번 프로젝트를 마치고 공부하면서
이번 기술 블로그는 Kafka를 알아보면서 튜터님께서 추가로 함께 공부해보기를 추천해주신 Flink라는 기술 스택을 알아보려고한다.
그래서 Flink는 어떻게 작동되고 어떤 특징을 갖고 있는지 알아보자
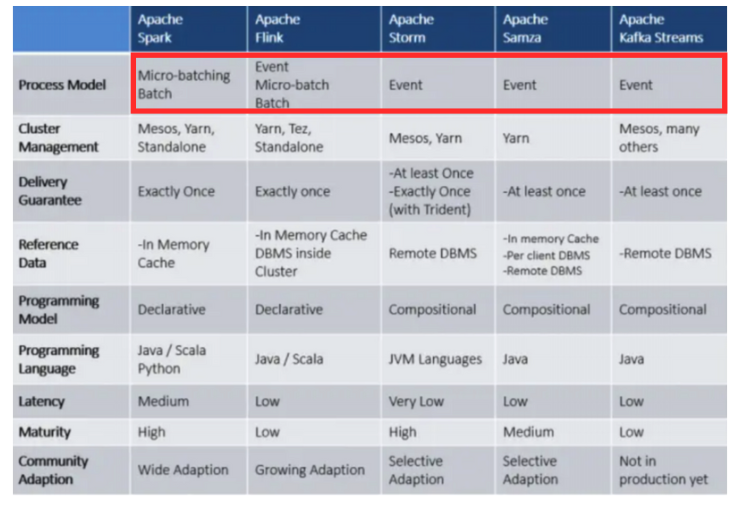
비교군들과 함께 각 기술의 처리 방식을 봐보면 배치 프로세싱과 실시간 처리 방식이 존재하는데 Flink는 이 가지 모두 가능하다. BatchPrcoessing은 실시간이 아닌 일정 주기를 가지고 배치 처리를 통해 수집한 데이터를 DB에 일괄적으로 전달하는 방식이다. 처리량이 많을 경우 이렇게 배치를 사용하는데 처리량이 많기 때문에 처리속도는 늦지만 정확히 전달할 수 있다는 장점이 있다.
반대로 실시간 처리는 객체의 상태변화에 집중하여 실시간으로 변동되고 보여줘야 하는 것들에 대해서 다뤄진다. 물류 시스템의 경우 재고가 감소되면 그 즉시 반영되어야 하기 때문에 이런 실시간 프로세스를 사용한다. 오른쪽 표를 보면 Flink는 Event(실시간 처리)와 Batch방식 모두가 가능한 것으로 확인할 수있다.

다음으로 이벤트 프로세스 과정의 종류에 대해서 알아보자.
Simple/Event Stream / Complex Event로 나눠서 확인해 볼 수 있다. 이 중 Flink는 Complex Event 방식에 해당되는데 실시간으로 정보의 흐름을 처리할 뿐만 아니라 그 이후에 발생되는 상황들에 대한 추가적인 행위가 가능하다. 예시와 같이 주식에서 등락이라는 이벤트가 발생하면 등락이라는 이벤트를 처리할 수 있는 추가적인 알람, 데이터 집계, 변환등의 행위가 가능하다.

이제 Flink에서 어떻게 데이터를 집계/변환 등의 행위를 할 수 있는지 확인해보자.
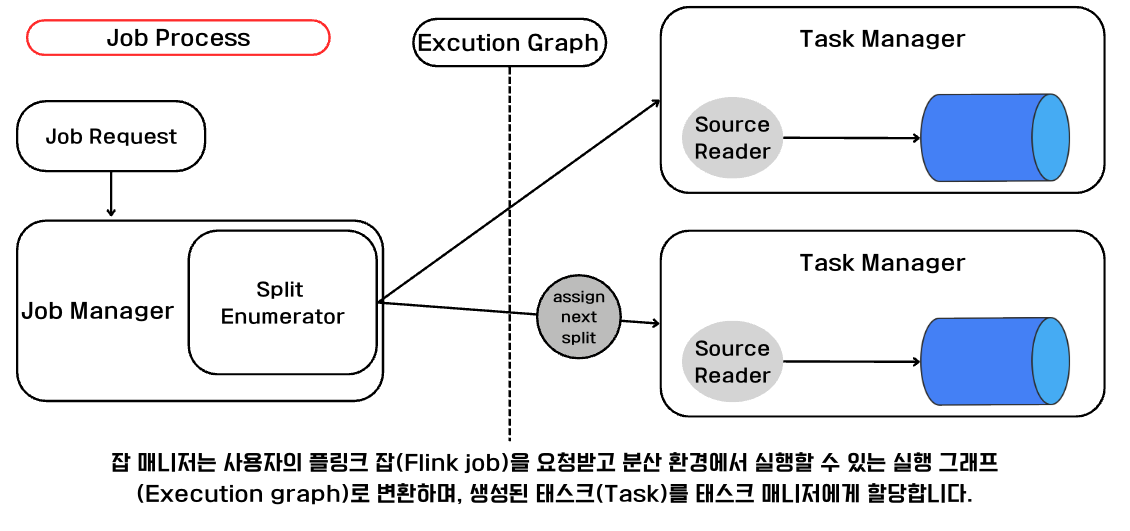
Flink에는 Job과 Task가 존재한다. Job은 들어오는 자료들(메세지 큐에서 수행된 이벤트)에 대해 Job Manager가 이를 확인하고 Spli Enumerator가 Task Manager에게 split이라는 단위로 데이터를 전달한다.
이렇게 요청을 받고 분산환경에서 실행할 수 있는 것을 실행 그래프라고 하며, Task Manager는 Source Reader에서 데이터를 전달받아 데이터의 집계/변환/결합 등의 행위를 수행한다.
이 다음으로 Task내부는 어떻게 작동되는지 알아보자
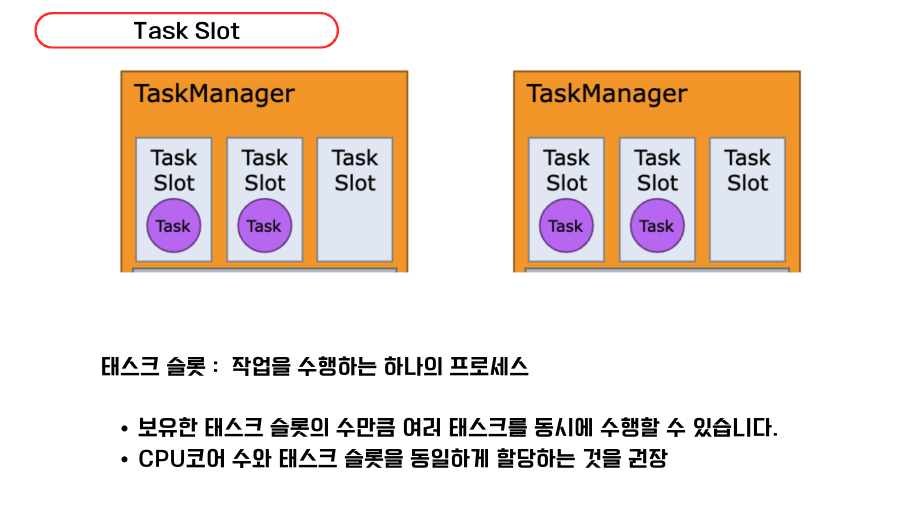
태스크 내부에는 Task Slot이 존재하고 이는 우리가 아는 프로세스와 같다. 하나의 Slot마다 Task가 처리되고 이는 Kafka의 Consumer가 수행되는 과정과 유사하다.
태스크가 많아지는 만큼 자원도 그만큼사용하는 것이기에 공식문서에서는 CPU코어 수와 태스크 슬롯을 동일하게 할당하는 것을 권장하고 있다.
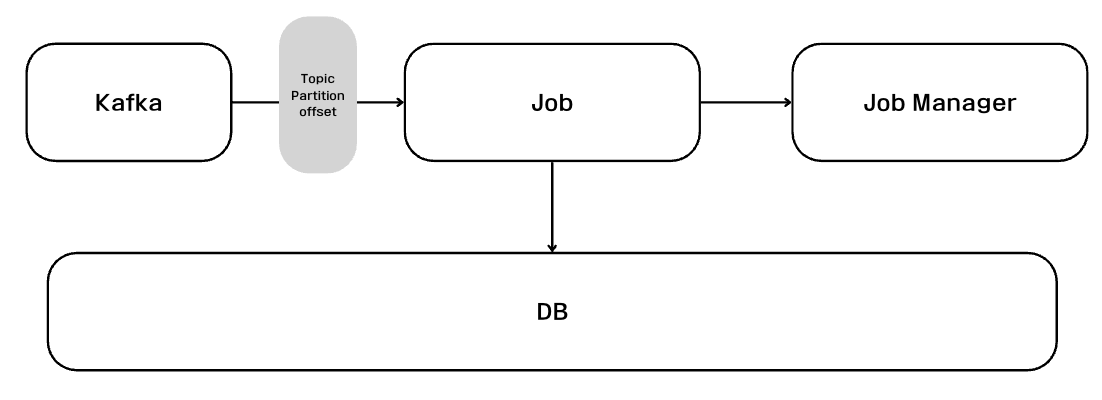
플링크에서도 데이터의 전달과정에서 데이터가 유실되는 문제가 발생할 수 있다. 이를 보완하기위한 CheckPoint 기술이 있다. Job에 들어온 Job Request 데이터를 DB에 저장하고 수행 중 장애가 발생할 경우 백업이 가능하도록 구축되어 있다.
다음으로 Task에서 어떤 수행이 이뤄지는지 확인해보자.
3가지로 구분되어 작업이 수행된다.
첫 번재로 받은 데이터를 Source Operators에서 받아 필요한 부분에 로직을 적용하고 Transformation Operators에서 데이터 변환이 이뤄지며 Sink Operators에서 데이터를 반환한다. 이 과정은 단독적으로도 가능하고 병렬적으로도 처리할 수 있는 기능을 제공한다.

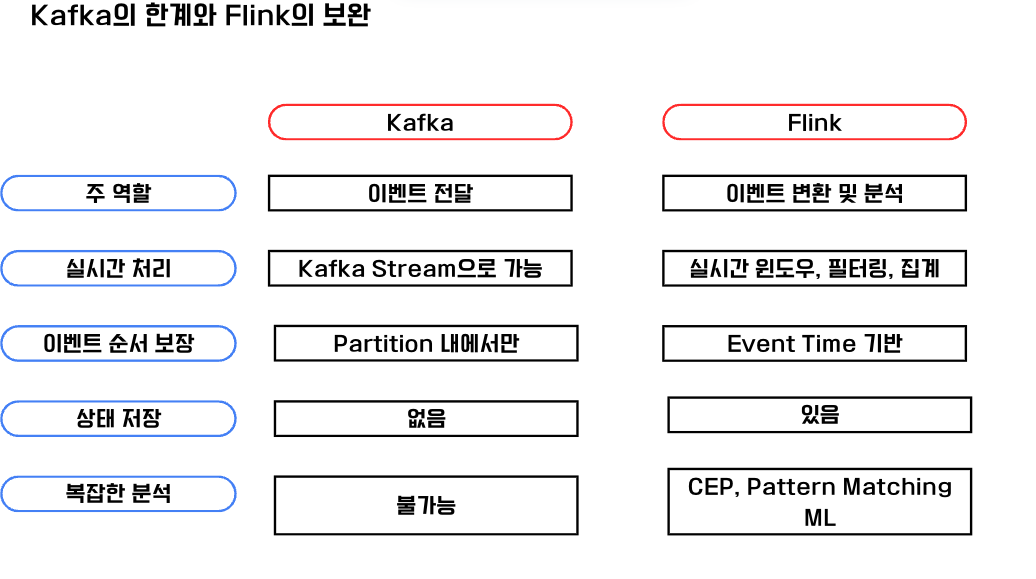
다음으로는 카프카에서 어떤한계가 있고 이것을 Flink로 어떻게 보완하는지 아래 비교내용을 살펴보자.
두 기술 스택 모두 이벤트를 통해 상태를 감지한다는 공통점이 있지만 Kafka는 이벤트를 전달할 뿐 그 이후 상태에 대한 저장, 복잡한 분석에 대한 기능을 제공하지 않는다. 또한 이벤트 순서는 partition내에서만 보장이 된다는 한계가 있다. 실시간 처리는 Kafka Stream을 사용해서 Producer의 Buffer Size를 조절하고 linger.ms 조절을 통해 배치처리를 수행한다.
반면에 Flink는 Event Time기반으로 실시간 윈도우, 필터링, 집계등을 처리할 수 있고 상태를 저장할 수 있기에 집계,변환,결합 처리가 가능하다. 아마 EventTimer기반이라는 부분이 가장 장점이지 않을까 싶다.
상태에 대해 복잡한 분석이 가능하기에 CEP, Pattern Matching, Maching Learning 부분에서 활용이 가능하다.
이와 같이 실제 현업에서는 Kafka로 메세지큐방식을 통한 데이터를 처리할 뿐만 아니라 데이터를 다시 한 번 저장하는 과정에서 변환,집계등을 수행하여 데이터의 상태를 체크하고 이후 서비스에 대한 전략을 달리 하는 방식까지 고려하기도 한다.
나는 카프카를 우선적으로 학습한 후에 Flink가 로컬에서 사용할 수 있는 스펙인지 확인후에 한 번 실습도 해보려고 한다.
다음에는 Kafka의 메세지에 대한 개념을 더 자세히 다뤄보겠다!
'Kafka' 카테고리의 다른 글
| [Kafka] 안정적인 이벤트 스트리밍 방식 설계하기 (1) | 2025.10.09 |
|---|---|
| [kafka+redisson] 올리브영의 재고관리시스템 분석 (0) | 2025.03.20 |
| [kafka+redisson] 올리브영의 재고관리시스템 분석 1편 (0) | 2025.03.18 |
| [Kafka] Consumer 올바르게 사용하기 (0) | 2025.03.10 |