2025.03.18 - [Kafka] - [kafka+redisson] 올리브영의 재고관리시스템 분석 1편
[kafka+redisson] 올리브영의 재고관리시스템 분석 1편
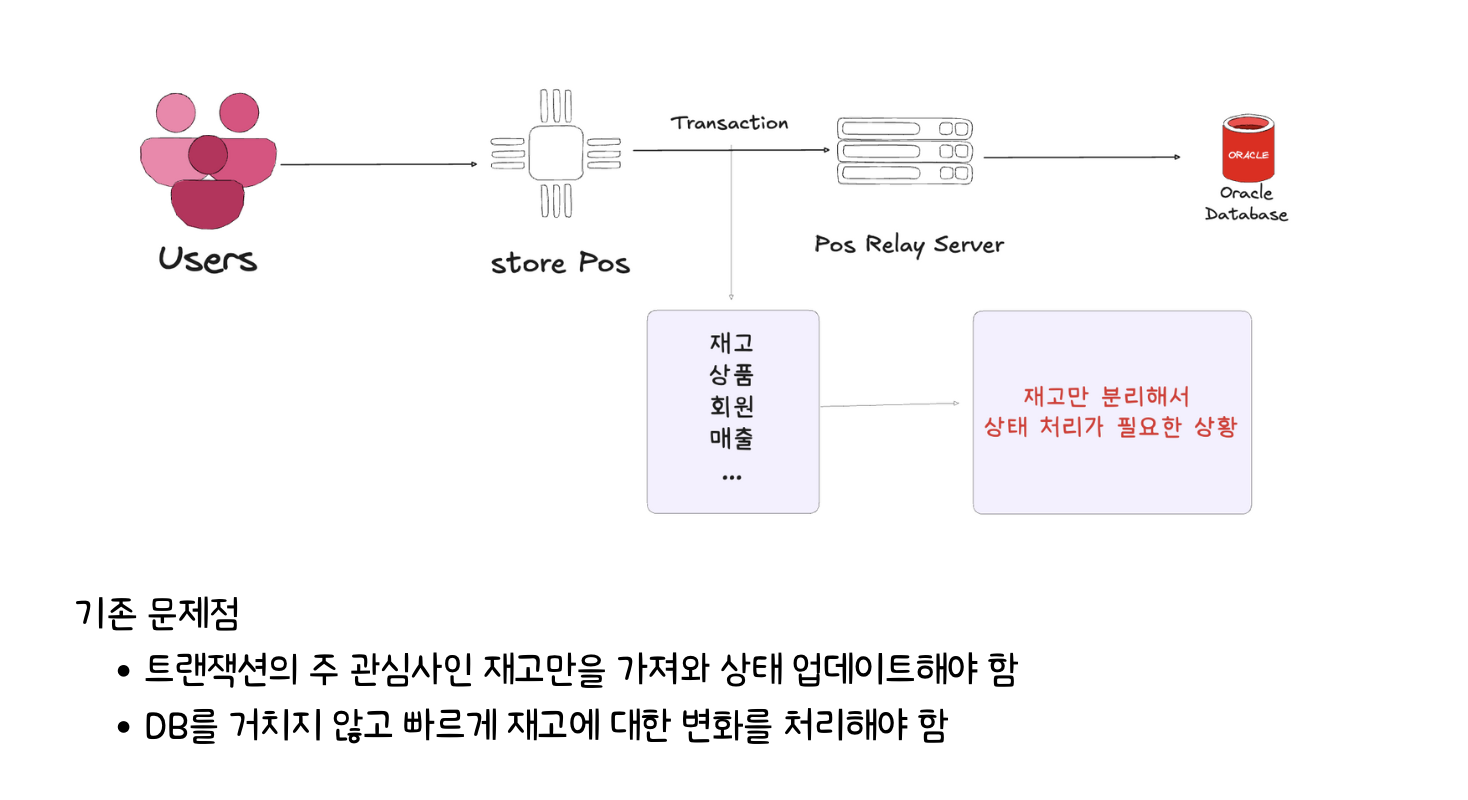
올리브영 재고 시스템 분석튜터님에게 발표한 내용을 기반으로 글을 작성하려고 한다. 위 그림은 레거시 서버에서의 올리브영이 겪고 있는 문제이다. 레거시 모놀리딕 서버에 여러 서버가 접근
sunro1994.tistory.com
이전 글에 이어 이번에는 Kafka를 활용한 물류 시스템 재고 처리에 대해서 다뤄보려고 한다.
Kafka 도입 이유
대표적인 메세지 큐는 Kafka, RabbitMQ, Redis Pub/Sub 정도로 알고 있다. 왜 물류 시스템에는 Kafka를 도입했을까?
트래픽 처리
Kafka는 RabbitMQ보다 더 많은 트래픽을 처리할 수 있는 구조를 가지고 있다. 토픽의 파티션을 늘리거나 컨슈머를 늘리고 Group을 만들어서 병렬작업이 가능한것이 수백만 트래픽을 감당할 수 있게 하는 이유가 아닐까 싶다.
또한 배치처리를 통해 한정적인 리소스를 효율적으로 쓸 수 있는 방법이 있다. RabbitMQ는 개별적인 메세지를 큐에 담아 전달하기에 많은 데이터를 처리하기 위해서는 Kafka가 물류 시스템에 적합하다고 생각했다.
데이터 보존 여부
Kafka는 데이터를 log를 기반으로 한 저장방식이 가능하기에 유실된 데이터를 복구할 수 있다는 장점이 있다. 물론 RabbitMQ도 다양한 방법으로 이러한 데이터를 보존할 수 있는 방법이 있겠지만 직접 구현해줘야 하는걸로 알고 있다. 이 부분은 조금 더 공부가 필요하다.
메세지 순서 보장
주문과 같은 도메인은 그 순서또한 중요하기에 먼저 주문한 유저에게 재고를 처리하고 감소시키는 것을 차례대로 진행해야 한다. 이 부분또한 같은 파티션이라는 전제하에 가능하지만 그 안에서는 Offset을 사용해서 순서대로 컨슈머들이 가져가서 처리하는 것을 확인할 수 있다.
RabbitMQ도 단일 컨슈머에서는 큐에서 순서대로 가져갈 수 있지만 여러개의 컨슈머가 있을 경우에는 누가 먼저 가져갈지 보장할 수 없다.

Kafka 도입 전
카프카 도입 이전에는 하나의 트랜잭션에 여러개의 도메인이 함께 묶여 데이터가 전송되었다. 그렇기에 재고만을 처리할 수 있는 방법이 필요했고 이를 DB를 거치지 않고 빠르게 재고에 대한 변화를 감지하고 전파할 수 있는 방법이 필요했다. DB를 거치는 방법은 파일시스템까지 접근해야 하기에 비교적 시간이 더 많이 걸리기 때문이다.
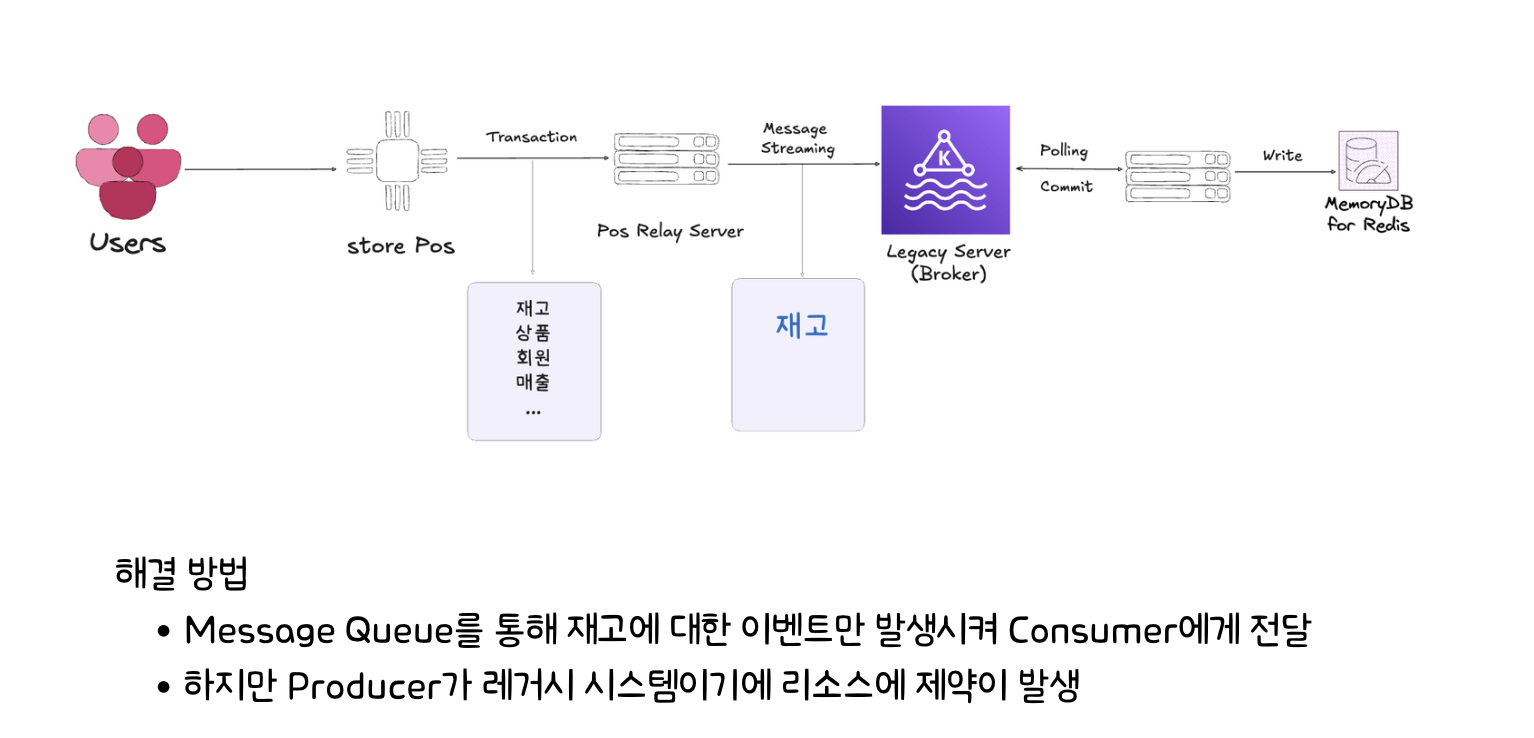
Kafka 도입 이후
카프카 도입 이후에는 Inmemory DB 인 MemeryDB를 사용해서 빠른 처리가 가능했으며 재고에 대한 이벤트만을 발생시켜 컨슈머에게 전달하는 방식으로 개선되었다. 하지만 이 부분에서도 고려해야 할 점이 Borker Server가 legacy한 서버이기에 자원의 제약이 많이 따른다. 한정적인 자원을 처리하기 위해 Batch를 사용해서 데이터를 일괄적으로 처리하게 된다. 배치 처리과정에서는 linger.ms라는 설정과 producer buffer memory , partition 개수, Batch 사이즈, Consumer Group, 오토 커밋여부등 고려해야 할 부분이 정말 많다.
이 설정들에 대해 간단히 설명하자면 아래와 같다.
linger.ms : batch를 전송하는 주기를 설정할 수 있다. 10ms라고하면 10ms가 되었을때 배치를 보내거나 그 이전에 배치사이즈가 모두 차면 전달한다. 이때 배치사이즈를 Producer쪽에서 먼저 압축하는 것이 좋을듯 하다. 전달시 사이즈가 줄어들기 때문에 더 빠르고 효율적으로 전송할 수 있다. 하지만 받는 쪽이 압축을 해제해야 한다는 단점이 생긴다.
producer buffer memory : producer가 kafka 서버로 데이터를 보내기 전에 잠시 기다리는 버퍼 메모리 공간을 의미한다.
batch size : 기본값은 16KB이다. 배치 크기를 늘리면 처리량, 요청 효율이 늘어나지만 그렇다고 너무 크게 잡아선 안된다. 네트워크에 부하가 생길 수 있을거라생각한다. 또한 배치보다 더 큰 메세지가 존재한다면 배치를 거치지 않고 지나간다. 배치 사이즈는 전송하는 메세지 및 파티션 용량 여부를 생각하고 설정할 듯 싶다.
Auto Commit : 실제로는 오토 커밋을 잘 쓰지 않는 것으로 보인다. 이 부분도 트레이드 오프나 어떤 도메인인지에 따라 다르겠지만 수동 커밋으로 acknowldeg를 날리는 것이 데이터 유실을 최소화 할 수 있다는 장점이 있기에 수동 커밋을 주로 사용하는 듯 싶다.

'Kafka' 카테고리의 다른 글
| [Kafka] 안정적인 이벤트 스트리밍 방식 설계하기 (1) | 2025.10.09 |
|---|---|
| [Flink] Kafka 의 한계점과 그를 보완할 수 있는 Flink (1) | 2025.03.26 |
| [kafka+redisson] 올리브영의 재고관리시스템 분석 1편 (0) | 2025.03.18 |
| [Kafka] Consumer 올바르게 사용하기 (0) | 2025.03.10 |