올리브영 재고 시스템 분석

튜터님에게 발표한 내용을 기반으로 글을 작성하려고 한다. 위 그림은 레거시 서버에서의 올리브영이 겪고 있는 문제이다. 레거시 모놀리딕 서버에 여러 서버가 접근하여 재고를 파악하기 때문에 트래픽이 몰리는 피크 시간대에 DB에 부담이 전해질 수 있는 상황이다. 이를 해결하기 위한 올리브영의 기존의 시도는 무엇이 있을까?
배치 + 캐시

캐시처리를 통해 RDB까지 접근하지 않아도 인메모리방식으로 빠르게 데이터를 조회할 수 있도록 하고, 쓰기 처리는 배치작업을 통해 일정량을 묶어 주기적으로 처리할 수 있는 방식을 사용한 것으로 보았다.
이 방식에서도 분명 한계점은 존재한다. Caching처리는 TTL이 존재하기에 만료시간에는 DB에 다시 접근해야 할 수 있고 DB와 캐시의 정합성또한 고려해봐야 한다.
배치 작업은 중간에 문제가 생길경우 데이터 유실이나 지연이 발생할 수 있어 여러 상황에 대비해줘야 한다.
그렇다면 이 방법에서 더 나아가 올리브영은 어떤 시도를 하였을까?
올리브영의 목표

다음과 같이 빠르게 처리한 데이터를 메모리 DB에 저장하고 이를 유연하고 관리가 편한 시스템인 AWS으로 서버를 관리하며, ELK를 통해 사용자의 행동을 분석하고 재고 데이터를 모니터링했다. 또한 재고에 대한 상태 변화는 Kafka를 사용하여 대용량 트래픽을 대처할 수 있도록 처리했다.
이 과정에 대해서 하나씩 알아보도록 하자. 우선 Redis의 redisson을 사용한 분산 락 및 동시성 처리이다.
Redisson - 동시성 및 분산 락 처리
왜 동시성 및 분산 락에 대한 처리가 필요할까?

여러 서버에서 동시에 재고에 대해 접근할 경우 이에 대한 접근 순서를 제한해 주지 않으면 레이스 컨디션이 발생하기 때문에 값을 수정하려는 작업이 동시다발적으로 발생해 원자적인 처리가 힘들다. 또한 재고가 얼마 남지 않은 상황에서 트래픽이 몰릴경우 재고가 음수가 되거나 잘못 반영될 위험이 있다.
이를 DB로 처리한다면 낙관적 락, 비관적 락중 비관적 락을 사용하게 될 텐데 요청이 증가하면 지연이 발생하기 때문에 사용자 경험에 불편함이 발생할 수 있다.
이를 처리하기 위해 도입한 Redisson 처리 과정을 살펴보자.

다음과 같은 과정을 통해 재고가 차례대로 감소하기 때문에 음수가 되거나 중복되는 작업으로 잘못된 처리가 발생할 일이 적어진다. 하지만 이렇게 락을 쓰면 분명 대기해야 하는 문제가 발생하고 이 부분에서 지연이 발생할텐데 이를 어떻게 해결할까?
이를 테스트 코드와 함께 성능을 측정해보고 알아보자
Rdisson의 Pub/Sub 기반 이벤트 처리 방식
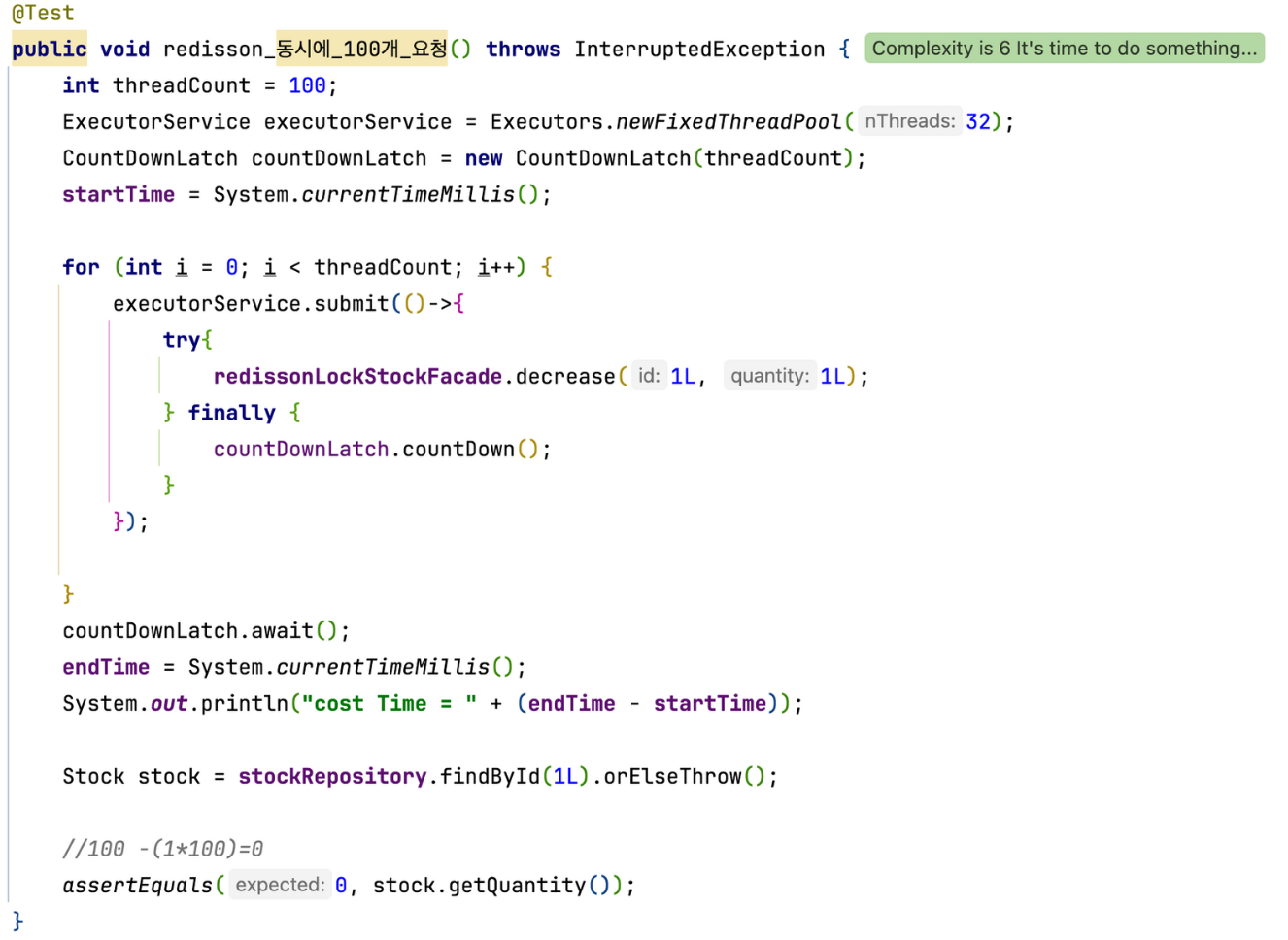

Redisson이 가장 빠른 이유
다음과 같은 이유로 Redisson을 사용하게 되었다고 생각한다. 분명 비관적 락도 빠른 속도가 발생했지만 분산환경에서 락을 처리하는 기능은 없다고 알기에 고려하지 않았다. 또한 Redis를 사용한 캐시처리가 더 효율적이라 생각했다.
1. Pub/Sub 기반으로 락 해제 후 즉시 다음 요청 실행 가능 → 불필요한 락 대기 시간 제거
2. 자동 갱신(LeaseTime) 기능 제공 → 락이 예기치 않게 해제되는 문제 방지
3. Redis 클러스터 및 Sentinel 환경에서도 안정적으로 동작
4. 비효율적인 락 재시도가 없음 (Optimistic Lock 대비 충돌 발생률 낮음)
이러한 이유로 올리브영에서는 재고에 대한 동시성을 제어하고 분산환경을 통제할 수 있었다. 다음 포스팅에서는 kafka를 어떻게 다뤘는지 확인해보자!
'Kafka' 카테고리의 다른 글
| [Flink] Kafka 의 한계점과 그를 보완할 수 있는 Flink (1) | 2025.03.26 |
|---|---|
| [kafka+redisson] 올리브영의 재고관리시스템 분석 (0) | 2025.03.20 |
| [Kafka] Consumer 올바르게 사용하기 (0) | 2025.03.10 |