데이터베이스 인덱스(Index)란? 인덱스가 많아지면 생기는 문제
데이터베이스를 다루다 보면 '인덱스(Index)'라는 개념을 자주 접하게 된다. 인덱스는 데이터 검색 속도를 향상시키는 핵심적인 요소지만, 무분별하게 생성하면 오히려 성능 저하를 초래할 수 있다. 이번 글에서는 인덱스의 의미와 사용해야 하는 경우, 그리고 인덱스가 많아질 때 발생하는 문제까지 논리적으로 정리해 보겠다.
1. 인덱스(Index)란?
인덱스(Index)는 데이터베이스 테이블에서 특정 컬럼의 값을 빠르게 찾을 수 있도록 도와주는 자료구조이다. 책의 목차와 비슷한 역할을 하며, 특정 데이터를 검색할 때 테이블 전체를 탐색하는 것이 아니라, 인덱스를 통해 빠르게 원하는 데이터를 찾을 수 있다.
인덱스의 기본 개념과 종류
1) B-Tree (Balanced Tree) 인덱스
B-Tree 인덱스는 대부분의 관계형 데이터베이스에서 기본적으로 사용하는 인덱스 구조로, 균형 트리(Balanced Tree) 구조를 이용하여 검색 속도를 높인다. 각 노드는 정렬된 상태로 유지되며, 검색, 삽입, 삭제가 빠르게 수행된다.
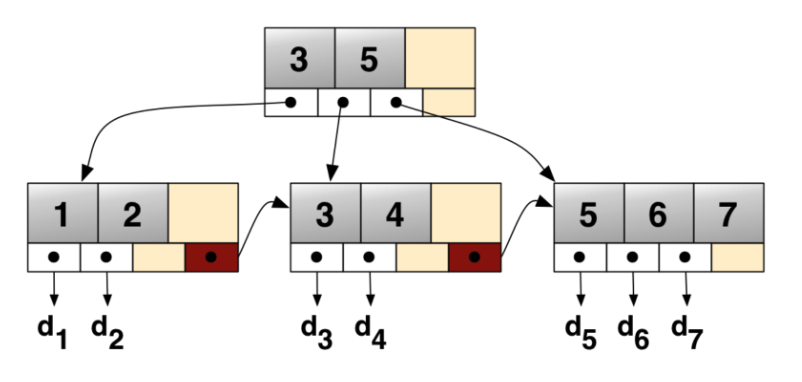
B-Tree의 주요 변형 종류:
- B+Tree: 리프 노드에서만 실제 데이터를 저장하며, 리프 노드끼리 연결 리스트로 연결되어 있어 범위 검색 성능이 뛰어나다.
- B*Tree: B+Tree의 변형으로, 노드 분할을 줄이기 위해 더 많은 데이터를 저장할 수 있도록 최적화된 구조이다.
- B#Tree: 인덱스 유지 비용을 낮추기 위해 주어진 범위 내에서 최적의 균형을 유지하는 방식으로 설계되었다.
예시:
CREATE INDEX idx_customer_id ON orders (customer_id);이렇게 생성된 B-Tree 인덱스는 customer_id 컬럼을 기준으로 정렬된 트리 구조를 형성하며, 특정 고객의 주문 데이터를 빠르게 검색할 수 있다.
2) Hash 인덱스
해시 테이블을 기반으로 한 인덱스로, 정확한 값 매칭이 필요한 경우 유용하다. 범위 검색이 어렵고, = 연산을 통한 조회에서만 강력한 성능을 발휘한다.
예시:
CREATE INDEX idx_product_code ON products USING HASH (product_code);이 인덱스는 product_code의 정확한 일치 검색에서만 빠른 속도를 제공한다.
B-Tree가 Hash 인덱스보다 더 많이 사용되는 이유
- 범위 검색 지원: B-Tree는 데이터가 정렬된 상태로 유지되므로
BETWEEN,>=,<=같은 연산을 빠르게 수행할 수 있다. 반면, Hash 인덱스는 키-값 매칭을 위한 구조라 범위 검색이 불가능하다. - ORDER BY와 GROUP BY 최적화: B-Tree는 데이터를 정렬된 상태로 유지하므로 정렬이나 그룹화 연산에서 추가적인 비용 없이 성능을 높일 수 있다.
- 다양한 비교 연산 지원: B-Tree는
=,<,>,LIKE 'prefix%'같은 다양한 연산을 최적화할 수 있지만, Hash 인덱스는=연산에만 최적화되어 있다. - 충돌 문제 없음: Hash 인덱스는 해시 충돌이 발생할 수 있어 조회 성능이 일정하지 않지만, B-Tree는 항상 일정한 성능을 보장한다.
- 멀티 컬럼 인덱스 가능: B-Tree는 다중 컬럼을 포함하는 복합 인덱스를 만들 수 있어 복잡한 검색 조건에서도 성능 최적화가 가능하다.
2. 인덱스를 사용해야 하는 경우
인덱스는 검색 속도를 높이는 데 유용하지만, 모든 경우에 적합한 것은 아니다. 적절한 경우에 사용해야만 성능을 최적화할 수 있다.
2.1 인덱스를 적용해야 하는 경우
- WHERE 절에서 특정 컬럼을 자주 조회하는 경우
customer_id컬럼에 인덱스가 없으면 테이블 전체를 검색(Full Table Scan)해야 하지만, 인덱스를 적용하면 해당 고객의 주문 정보를 빠르게 찾을 수 있다.
SELECT * FROM orders WHERE customer_id = 'C12345';- JOIN 조건으로 자주 사용되는 컬럼
customer_id컬럼에 인덱스가 있으면 조인 성능이 향상된다.
SELECT * FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE c.name = 'John Doe';- ORDER BY, GROUP BY 절에서 정렬/그룹화할 때
category컬럼에 인덱스를 설정하면 그룹화 연산이 빨라진다.
SELECT category, COUNT(*) FROM products GROUP BY category;- 대량 데이터에서 특정 범위 검색을 수행할 때
sale_date컬럼에 인덱스가 없으면 전체 테이블을 스캔해야 하지만, 인덱스를 설정하면 원하는 범위 내의 데이터만 빠르게 찾을 수 있다.
SELECT * FROM sales WHERE sale_date BETWEEN '2024-01-01' AND '2024-02-01';
2.2 JPA에서 자동으로 생성되는 인덱스
JPA에서는 특정 어노테이션을 사용하면 자동으로 인덱스가 생성된다.
- 기본 키(@Id) 컬럼: 기본적으로 클러스터드 인덱스가 생성된다.
- Unique 제약 조건이 있는 컬럼:
@Column(unique = true)설정 시 자동으로 인덱스가 추가된다.
예시:
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String email;
}위 코드에서 email 컬럼은 JPA가 자동으로 유니크 인덱스를 생성한다.
3. 인덱스를 많이 만들면 생기는 문제
인덱스가 많을수록 검색 속도가 향상될 것 같지만, 너무 많은 인덱스를 만들면 오히려 성능 저하를 유발할 수 있다.
그러므로 한 테이블당 3~5개 정도로 제한을 두고 생성하는 것을 권장한다.
3.1 데이터 삽입, 수정, 삭제 성능 저하
- 데이터가 변경될 때마다 인덱스도 함께 갱신되어야 하므로,
INSERT,UPDATE,DELETE속도가 느려진다.
3.2 스토리지 공간 증가
- 인덱스는 별도의 저장 공간을 차지하며, 너무 많으면 디스크 사용량이 증가한다.
3.3 불필요한 인덱스 탐색 비용 증가
- 옵티마이저(Optimizer)는 실행 계획을 수립할 때 인덱스를 참고하는데, 인덱스가 너무 많으면 최적의 인덱스를 선택하는 데 오버헤드가 발생할 수 있다.
'면접 준비' 카테고리의 다른 글
| [면접 스터디용 질문 리스트] OS / DB / NETWORK/ MSA (0) | 2025.03.02 |
|---|---|
| [면접 스터디용 질문 리스트] JAVA/SPRING/JPA/Redis/ 면접 질문 리스트 10개 씩 (0) | 2025.03.02 |
| [컴퓨터 구조 + 캐시 ] 우리가 Redis를 사용해서 캐시 메모리를 쓰는 이유 (1) | 2024.12.05 |
| 면접 준비시 반드시 피해야 할 것들! (2) | 2024.11.12 |
| 백엔드 자바 CS 면접 빈출 질문 대비하기 - 데이터 베이스 개념 정리 1 (0) | 2024.08.22 |