해당 자료는 데브원영 DVWY강사님의 자료를 기반으로 정리하였습니다.
이미지들은 제가 직접 테스트 후 변경할 예정입니다.
문제될 시 비공개 처리 후 수정하겠습니다!
카프카 사용 이전에는 end to end로 많은 문제점이 발생했다. 링크드인에서는 이러한 문제를 해결하기 위해서 데이터 전송을 실시간 처리도 가능하면서 확장에 용이한 이런 시스템을 개발하기 위해 만든 시스템이다.
문제점
- EndToEnd 연결 방식의 아키텍처
- 데이터 연동의 복잡성 증가(하드웨어, 운영체제, 장애 등)
- 각기 다른 데이터 파이프라인 연결 구조
- 확장에 엄청난 필요
문제 해결 요구 사항
- 모든 시스템으로 데이터를 전송 실시간 처리도 가능한 것
- 데이터가 갑자기 많아지더라도 확장이 용이한 시스템이 필요함

출처 : 데브원영 DVWY
해결방법 : 카프카
- 프로듀서와 컨슈머로 분리
- 메세지 데이터를 여러 컨슈머에게 허용한다.
- 높은 처리량을 위한 메시지 최적화
- 스케일 아웃 가능
- 관련 생태계 제공
실제 SK Planet 데이터 플랫폼 아키텍처
- Source에서 전달되는 데이터들이 Log Definition Tool을 통해 정제되고 최적의 데이터들이 카프카와 배치를 통해 hadoop으로 consuming 된다.

kafka borker
- 실행된 카프카 애플리케이션 서버 중 1대
- 3대 이상의 브로커로 클러스터 구성
- 주키퍼와 연동(~2.5.0버전까지)
- 운영상의 이슈로 주키퍼가 분리될수도 있다는 전망이 있다.
- 하지만 아직 카프카를 운영하는데 주키퍼가 필요한 상황이다.
- n개 브로커 중 1대는 컨트롤러 기능을 수행한다.
- 컨트롤러 : 각 브로커에게 담당 파티션 할당을 수행한다. 브로커 정상 동작 모니터링을 관리하면 누가 컨트롤러인지는 주키퍼에 저장한다.
Record
- Producer
Producer는 String,String으로 키와 메세지 타입을 지정했다.
new ProducerRecord<String,String>("topic","key","message");
- Consumer
Consumer또한 Producer에 맞춰 String,String으로 메세지 타입을 지정했다.
ConsumerRecords<String,String> records = consumer.poll(1000);
for(ConsumerRecord<String,String> record : records){
...
}
객체를 프로듀서에서 컨슈머로 전달하기 위해 Kafka 내부에 byte 형태로 저장할 수 있도록 직렬화/역직렬화하여 사용한다.
기본 제공 직렬화 class는 StringSerializer, ShortSerializer 등이 있다.
커스텀 직렬화 또한 가능하여 POJO는 Custom Object 직렬화/역직렬화가 가능하다.
Topic 과 Partition
- Topic은 메세지 분류 단위이다.
- Consumer, Producer는 최소한 하나의 토픽을 가지고 있어야 한다.
- N개의 파티션이 할당 가능하여 하나 이상의 파티션을 생성하여 관리할 수 있다.
- 각 파티션마다 고유한
offset이 존재한다. - 메세지 처리순서는 파티션 별로 유지 관리된다.

Producer & Consumer
- 프로듀서는 레코드를 생성하여 브로커에게 전송
- 전송된 레코드는 파티션에 신규 오프셋과 함께 기록
- 컨슈머는 브로커로부터 레코드를 요청하여 가져간다.(Polling기준 , 절대 브로커가 컨슈머로 보내는것이 아니다.)

사진에서 보듯이 ConsumerA는 offset 9번을 가져간다면 1~8번을 가져갔다는 뜻이 되기도 한다.
Producer acks
이 설정은 브로커 하나일때에는 의미가 없는 설정이다.
- akcs =0
- 가장 속도가 빠르지만 유실 가능성이 있다.
- 프로듀서가 브로커와 소켓연결을 맺어 보낸 즉시 성공으로 간주
- 브로커가 정상적으로 받아서 저장했는지 모름
- 전송 속도가 중요하고 일부 유실되어도 무관한 데이터에서 사용
- 센서 데이터 등
- acks = all or -1
- 모두 ISR 상태가 될때까지 기다린다 만약 3개의 브로커에서 레플리케이션이 3이라면 9만큼의 시간을 기다려야하는 것
- 속도가 가장 느리지만 손실 가능성이 없다
- 카드정보, 은행관련 정보등에 사용
- SK에서는 all로 적용
- acks = 1 (default) 보통 속도, 유실 가능성이 있다.
- 리더 파티션에 저장되었는지는 확인한다.
- 팔로워 파티션에 저장되었는지는 모른다.
- 리더 파티션에 저장되고 해당 브로커가 죽으면 데이터가 유실될 가능성이 있다.

Producer Options
필수 옵션
1. bootstrap.servers : 카프카 클러스터에 연결하기 위한 브로커 목록
2. key.serializer : 메시지 키 직렬화에 사용되는 클래스
3. value.serializer : 메시지 값을 직렬화 하는데 사용되는 클래스
선택 옵션
1. acks : 레코드 전송 신뢰도 조절(리플리카)
2. comression.type : snappy, gzip, lz4 중 하나로 압축하여 전송
3. retries : 클러스터 장애에 대응하여 메시지 전송을 재시도하는 회수
4. buffer.memory : 브로커에 전송될 메시지의 버퍼로 사용 될 메모리의 양
5. batch.size : 여러 데이터를 함께 보내기 위한 레코드 크기
6. linger.ms : 현재의 배치를 전송하기 전까지 기다리는 시간
7. client.id : 어떤 클라이언트인지 구분하는 식별자
Spring에서는 다음과 같이 설정할 수 있다.
- yml
spring:
kafka:
bootstrap-servers: localhost:9092 # 1. 필수 옵션 (브로커 목록)
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 2. 필수 옵션 (키 직렬화)
value-serializer: org.apache.kafka.common.serialization.StringSerializer # 3. 필수 옵션 (값 직렬화)
acks: all # 1. 선택 옵션 (메시지 전송 신뢰도)
compression-type: gzip # 2. 선택 옵션 (압축 방식)
retries: 3 # 3. 선택 옵션 (전송 실패 시 재시도 횟수)
buffer-memory: 33554432 # 4. 선택 옵션 (버퍼 메모리 크기)
batch-size: 16384 # 5. 선택 옵션 (배치 크기)
linger-ms: 1 # 6. 선택 옵션 (전송 전 대기 시간)
client-id: my-producer # 7. 선택 옵션 (클라이언트 식별자)
- config 파일
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // 1. 필수 옵션 (브로커 목록)
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 2. 필수 옵션 (키 직렬화)
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 3. 필수 옵션 (값 직렬화)
// 선택 옵션 적용
configProps.put(ProducerConfig.ACKS_CONFIG, "all"); // 1. 신뢰도 설정
configProps.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "gzip"); // 2. 압축 방식
configProps.put(ProducerConfig.RETRIES_CONFIG, 3); // 3. 재시도 횟수
configProps.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // 4. 버퍼 메모리
configProps.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 5. 배치 크기
configProps.put(ProducerConfig.LINGER_MS_CONFIG, 1); // 6. 대기 시간
configProps.put(ProducerConfig.CLIENT_ID_CONFIG, "my-producer"); // 7. 클라이언트 ID
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Consumer
- 데이터를 가져가는 polling 주체
- commit을 통해 읽은 consumer offset을 카프카에 기록
- RDBMS, NoSQL, S3, FileSystem등에 데이터를 저장할 수있다.
필수 옵션
- bootstrap.servers : Kafka Cluster에 연결하기 위한 브로커 목록
- group.id : Consumer Group Id
- key.deserializer : 메세지 키 역직렬화에 사용되는 클래스
- value.deserializer : 메시지 값을 역직렬화 하는데 사용되는 클래스
선택 옵션
- enable.auto.commit : 자동 오프셋 커밋 여부, 속도가 가장 빠르지만 중복 또는 유실이 발생할 수 있다. 은행,카드 등의 곳에서 사용하면 안됨! 일부 데이터가 중복/유실되도 상관없는 센서, GPS에서 사용
- 예시) 커머스 장바구니 시스템, 카드사의 결제, 택배사의 SMS 발송
- 중복을 막을수 있는 방법은 오토 커밋을 사용하지 않는다.
- Kafak consumer의 commitSync(), commitAsync()를 사용한다.
commitSync : 동기 커밋(주로 사용)
ConsumerRecord 처리 순서를 보장한다.
커밋이 완료될때까지 block 처리하기때문에 가장 느리다.
poll() 메서드로 반환된 ConsumerRecord의 마지막 offset을 커밋
Map<TopicPartition, OffsetAndMetadata>을 통해 오프셋 지정 커밋 가능
commitAsync : 비동기 커밋
동기 커밋보다 빠르다.
중복이 발생할 수 있다.
ConsumerRecord 처리 순서를 보장하지 못한다.
- 일시적인 통신 문제로 이전 offset보다 이후 offset이 먼저 커밋 될 때
ConsumerRecord 처리 순서를 보장하지 못함
- 처리 순서가 중요한 서비스에서는 사용 제한



- auto.commit.interval.ms : 자동 오프셋 커밋일 때 interval 시간
- auto.offset.reset : 신규 컨슈머 그룹일 때 읽을 파티션의 오프셋 위치
- client.id : 클라이언트 식별 값
- max.poll.records : poll() 메서드 호출로 반환되는 레코드 최대 개수
- session.timeout.ms : 컨슈머가 브로커와 연결이 끊기는 시간
Consumer rebalance
- 컨슈머 그룹의 파티션 소유권이 변경될 때 일어나는 현상
- 리밸런스를 하는 동안 일시적으로 메시지를 가져올 수 없다
- consuerm.close(), consuemr의 세션이 끊겼을때
- 리밸런스 발생 시 데이터 유실/중복 발생 가능성 있음 - commitSync(), unique key로 적재하는 방법으로 데이터 유실/중복 방지
- 세션 체크시간은 하트비트 체크 시간 *3으로 대부분 설정한다고 한다. (하트비트 3초 -> 세션 타임아웃 10초 -> 리밸런싱 발생)

Consumer rebalance listener
- 리밸런스 발생에 따른 offset commit에 사용
- 리밸런스 시간 측정을 통한 컨슈머 모니터링에 사용

Consumer Wakeup

1. poll()호출
마지막 커밋된 오프셋이 100
recoreds 100개 반환 (101~200)
2) records loop 구문 수행
3) 오프셋 print중 sigkill 호출한 경우 151~200오프셋 미처리, 커밋도 안되어있음

4) 다시 시작시 101번부터 처리 시작, 101~150번 중복 처리
이러한 상황을 방지하기 위해 wakeup을 사용하여 graceful shutdown 필수!

아래 예외 처리를 통해서 poll에서 문제가 발생했음을 로그로 명시하고 consumer가 수행한 것들을 commitSync하여 처리하고 consumer.close()하여 안전하게 종료시킨다.
최대한 레코드 단위로 커밋하여 유실을 최소화 시키는 것이다.

Consumer thread 전략
1. 1 process + 1 thread(Consumer)
- 프로세스 단위 실행/종료
- 다수의 컨슈머 실행 필요시 다수의 프로세스 실행 필요
2. 1 process + n thread(동일 컨슈머 그룹)
- 복잡한 코드
- 스레드 단위 실행/종료
- 다수 컨슈머 실행 시 다수 스레드 실행 가능
- 스레드간 간섭 주의(세마포어, 데드락 등)
3. 1 process + n thread(다수 컨슈머 그룹)
- 복잡한 코드
- 컨슈머 그룹별 스레드 개수 조절 주의
Consumer log
- 컨슈머 랙은 컨슈머의 상태를 나타내는 지표
- 컨슈머 랙의 최대값은 컨슈머 인스턴스를 통해 직접 확인 가능
- consumer.metrics()를 통해 확인할 수 있는 지표
- records-lag-max : 토픽의 파티션 중 최대 랙
- fetch-seze-avg : 1번 polling하여 가져올 때 레코드 byte 평균
- fetch-rate : 1초 동안 레코드 가져오는 회수
- consumer.metrics()를 통해 확인할 수 있는 지표

Consumer lag 수집의 문제점
- 컨슈머 인스턴스 장애가 발생하면 지표 수집 불가능
- 구현하는 컨슈머마다 지표를 수집하는 로직 개발 필요
- 컨슈머 랙 최대값만 알 수 있음
- 토픽에 파티션은 n개가 있을 수 있음
- 최대값을 제외한 나머지 파티션의 컨슈머 랙은 알 수 없음

이 모니터링을 위해 카프카 버로우, Confluent를 사용하여 랙 모니터링이 가능하다. 전체 랙을 한번에 수집하기 때문에 매우 편함(LinkedIn 오픈소스)


모니터링 툴에서 다음과 같은 상태를 반환해줄 수 있다.
Grafana를 통해 lack이 늘어나는 경우 slack 알람을 보내줄 수도 있다. Kibana는 AssertJ방식이므로 별도 설정이 필요한듯 하다.
Telegraf는 Input Plugin을 통해 데이터를 수집하고 ES, File, S3등으로 보내 줄 수 있다.
ok - 정상(Consumer lack이 정상적으로 줄어듬) / error - Consumer offSet이 늘어나지 않는 경우(polling 멈춤) / Warning- 컨슈머 랙이 계속 늘어남(컨슈머 처리 양이 적다는 뜻)
Kafka는 auto scale-down이 안된다. partition을 늘리게되면 영구적으로 늘어난다.
Kafka log and segment
- 실제로 메시지가 저장되는 파일시스템 단위
- 메시지가 저장될때는 세그먼트 파일이 열려있다.
- 세그먼트 시간 또는 크기 기준으로 닫힌다.
- 세그먼트가 닫힌 이후 일정 시간에 따라 삭제 또는 압축이 된다.
파티션 3개인 토픽과 컨슈머 1
현재 토픽에 파티션이 3개가 존재하고 컨슈머 1개가 토픽 파티션 3개에 할당되어 있는것을 확인할 수 있다.
컨슈머는 파티션 0,1,2번의 데이터를 계속해서 Polling해간다.
만약 컨슈머가 3개인 경우 각각의 파티션이 각각의 컨슈머와 할당이 되어서 1:1매칭이 된다.
컨슈머는 결국에는 파일에 저장, S3에 저장하는 처리를 할 텐데 컨슈머 한 대당 처리하는 시간이 한정적이기에 컨슈머를 여러개로 병렬처리한다면 각 파티션의 데이터를 각각의 쓰레드 또는 프로세스가 더 빠른속도로 처리할 수 있기 때문이다.
컨슈머가 4개가 된다면 한 대가 놀게 되는데 컨슈머는 파티션의 개수보다 같거나 더 작게 만들어야 한다. (단, 같은 컨슈머 그룹에 들어있을 경우)
만약 컨슈머 2번이 장애가 났다고 하자, 어떤 사유로 인해 프로세스나 서버가 종료된 경우 컨슈머 1번이 두 개의 파티션에 할당이 된다. 이러한 재할당이 되는 과정이 rebalance라고 한다. 이 재할당 과정에서 중단이 발생한다. 어떤 파티션이 어디 컨슈머에 연결되어야 할지 모르기에 재할당과정에서 일어나는 문제이다.
rebalance listener를 통해 이러한 문제들을 처리해야 한다.

2개 이상의 컨슈머 그룹
목적에 따라 컨슈머 그룹을 분리할 수 있다.
토픽안에 있는 파티션의 데이터들을 목적에 따라 분리하여 처리할 수 있다. 컨슈머 1번이 파티션 1번의 12번을 처리해도 컨슈머 b는 1번과 상관없이 파티션 1번의 12번에 접근하여 처리할 수 있다.
이미 처리중이고 스트리밍중인 부분은 그대로 처리하도록 하고 중간에 데이터가 재처리되어야 한다면 새로운 컨슈머 그룹을 만들어서 중간부터 재처리하도록 하기 위해서 컨슈머 그룹을 나누기도 한다.

애플리케이션 로그 적재용 컨슈머 그룹 2개
엘라스틱 서치 : 로그 실시간 확인용, 시간순 정렬
하둡 : 대용량 데이터 적재. 이전 데이터 확인용
- 데이터 양이 많아질수록 테라바이트, 페타 바이트가 될텐데 이때는 하둡을 사용해서 기록을 확인할 수 있다.
- 각 컨슈머 그룹은 장애가 격리가 되기 때문에 만약 Hadoop에 장애가 생기더라도 엘라스틱 서치는 문제없이 사용 가능하다.
- 하둡이 복구되면 중단된 시점부터 다시 데이터를 적재하기 시작한다.

Broker partition replication - 이슈 처리

3개의 파티션이 있을 때 만약 Broker#1이 문제가 생겨 partition#1이 사용하지 못하는 상황이 발생했다. 이때 KafkaBroker 이슈에 대응하기 위해 사용할 수 있는 방법은 복제이다.
파티션을 다른 브로커에 복제하여 이슈에 대응 할 수 있다.
기본적으로 복제하는 개수는 3으로 지정해주고 사용한다.

리더 파티션, 팔로워 파티션
리더 파티션은 카프카 클라이언트와 데이터를 주고 받는 역할을 한다.
팔로워 파티션은 리더 파티션으로부터 레코드를 지속적으로 복제하게 되는데 만약 리더 파티션이 동작 불가능한 경우 자동으로 팔로워 중 1개가 리더로 선출이 되고, 복구가 된 리더 파티션이 다시 작동될경우 기본적으로 새로운 리더가 유지되지만 수동으로 변경해줄 수 있다.
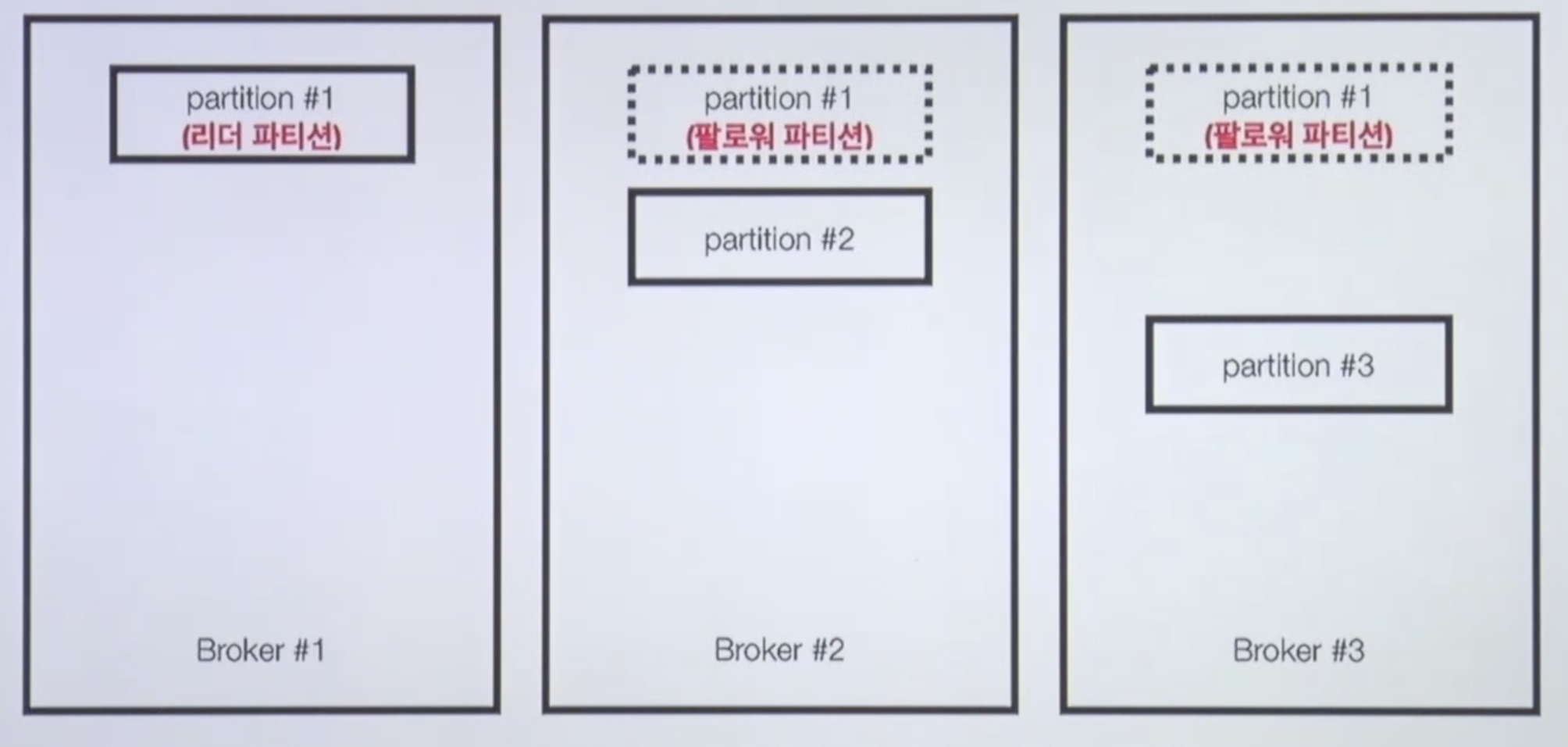
ISR(In-Sync Replica)
특정 파티션의 리더, 팔로워가 레코드가 모두 복제되어 sync가 맞는 상태를 말한다.
만약 리더 파티션 오프셋이 0
100까지 있다고 하면 나머지 팔로우 파티션도 100개라고 하면 이 상황에서도 ISR인 상황이라고 할 수 있다.
팔로우 파티션이 0
90까지 오프셋이 복사되어 있고, 리더 파티션이 0
100이라면 리더 파티션이 문제가 생겼을때 90
100번은 유실될 수 있다.
ISR이 아닌 상태에서 장애가 나면 unclea.leader.election.enable=false로 설정할 수 있다. 이렇게되면 아직 온전히 복사되지 않은 팔로우 파티션들을 대기시킬 수 있다. 유실되어도 상관없다면 true로 설정해준다.
Kafka rack-awareness
- 서버 rack은 하나의 파워로 구성되어 있거 여러개의 서버가 있다. 이를 방지하기 위해서 다음과 같이 설정할 수 있다.
- 하나의 랙에는 하나의 브로커만 설치할 수 있다.
- 다수의 Rack에 분산하여 브로커 옵션(broker.rack) 설정 및 배치를 할 수 있다.
Kafka Client
카프카 브로커와 클라이언트 버전은 하위호환이 확인이 필요하다.
Kafka Streams
데이터를 변환하기 위한 목적으로 사용하는 API이다.
스트릠 프로세싱을 지원하기 위한 다양한 기능을 제공한다.
- stateful , Stateless와 같이 상태기반 스트림 처리 가능
- Stream API, DSL(Domain Specific Language)를 동시 지원
- Exactly-once 처리, 고 가용성 특징
- Kafka Security(acl, sasl 등) 완벽 지원
- 스트림 처리를 위한 별도의 클러스터 불필요
Kafka Connect
카프카 클라이언트로 카프카로 데이터를 넣는 코드도 있지만 커넥트를 사용해서 데이터를 임포트,익스포트도 가능하다.
코드 없이 Configuration으로 데이터를 이동시키는 것이 목적이다.
- Standalone mode, distribution mode 지원
- REST api interface를 통해 제어
- Stream, Batch 형태로 데이터 전송이 가능하다
- 커스텀 connector를 통한 다양한 plugin이 제공된다.(File, S3, Hive, MySQL 등)

Kafka Mirror maker
특정 카프카 클러스터에서 다른 카프카 클러스터로 토픽과 레코드를 복제하는 툴이다.