MSA 환경을 구성하는데 있어 가장 먼저 개설하는 서버이다. 내가 사용한 기술은 Netflix가 개발한 Eureka라는 기술이며 서비스를 등록하고 디스커버리 하는 역할을 수행한다.
Netflix는 왜 MSA 환경이 필요했을까?
Netflix.io Github
Netflix MSA 사례 (출처 삼성SDS)
우리는 면접에서 언제든지 왜 MSA를 사용했어요? 왜 자바를 사용했나요? 라는 물음에 대답할 준비를 해야 한다... 남들이 다 하는 기술과 아키텍처이니까요.. 라고 할 순 없기에 모노리딕 서비스 아키텍처와 어떤 차별점이 있는지 어떤 장점이 있어서 대기업들이 넷플릭스 당하다 라는 말을 만들며 MSA 도입에 따라나서게 됐는지 알아보면 좋을 것 같다. 아래 내용은 위 링크에 대한 내용을 정리한 내용이기에 이미 읽고 왔다면 다음 목차로 넘어가도 좋다.
Neflix는 원래 비디오 가게?
넷플릭스는 지난 수십년간 많은 미디어 시장을 뒤집을 만큼 강자로 올라와 있다. 동영상 스트리밍 서비스를 통해 전 세계에서 영상을 시청중이며 넷플릭스는 이에 대비할 방법이 필요했다. 2007년에는 넷플릭스의 DB에 문제가 발생하여 서비스 장애를 서비스 유저들에게 겪게 하는 불상사가 생겼고, 이 시점에서 넷플릭스는 고가용성, 유연한 스케일링, 빠르고 쉬운 배포 전략을 적용할 수 있는 MSA를 도입하게 되었다고 한다. 이 기술을 도입하는데에는 무려 7년의 시간이 걸렸고 고맙게도 이 해결과정을 공유하기 위해 MSA 전환 기술을 오픈 소스로 공개했다고 한다.
MSA를 도입하면서 고민했던 내용들
MSA에서 가장 중요한 요소 중 하나는 자동 확장(Auto Scale-out)방식 이였다. 자동 확장 서비스에 트래픽이나 부하가 증가하는 경우 인스턴스를 추가로 생성해야 하고, 반대의 상황에서는 인스턴스를 제거해 나가는 기술이다.이 상황에서는 고려해야 할 부분이 많은데 인스턴스가 생겨나면 그때마다 해당 인스턴스에 대한 로드 밸런싱, 장애 대응 방식, 설정등을 수동으로 하나하나 설정해줘야 했다. 이러한 빈번함을 해결하는 것이 가장 중요했다고 생각한다. 그렇게 생겨난 것이 Spring Cloud Netflix이다. Spring Cloud Netflix에는 많은 넷플릭스 OSS가 통합되어 있다.
모든 기술을 설명할 순 없기에 각 기술을 내 프로젝트에 적용하면서 개념들을 설명해 보겠다.
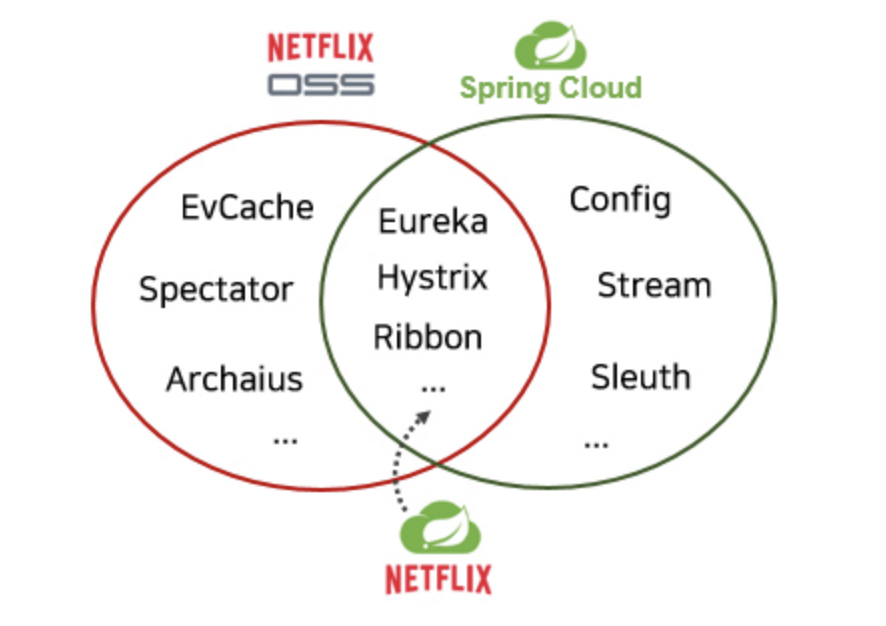
출처 : https://www.slideshare.net/balladofgale/spring-cloud-workshop
MSA 강의를 시작하면서 Service Discovery라는 단어는 처음 듣는 생소한 단어여서 이에 대한 개념을 확실히 짚고 넘어가기로 했다.
서비스 디스커버리란?
위에서도 말했듯이 MSA를 도입하면서 발생한 불편한 부분을 해결하는 방식이다.
Scale-out에서 발생하는 새로은 인스턴스들에 대해서 일일이 수동으로 설정하는 방식에서 불편함을 느끼고 이를 동적으로 해결하기 위한 개선 방식이다.
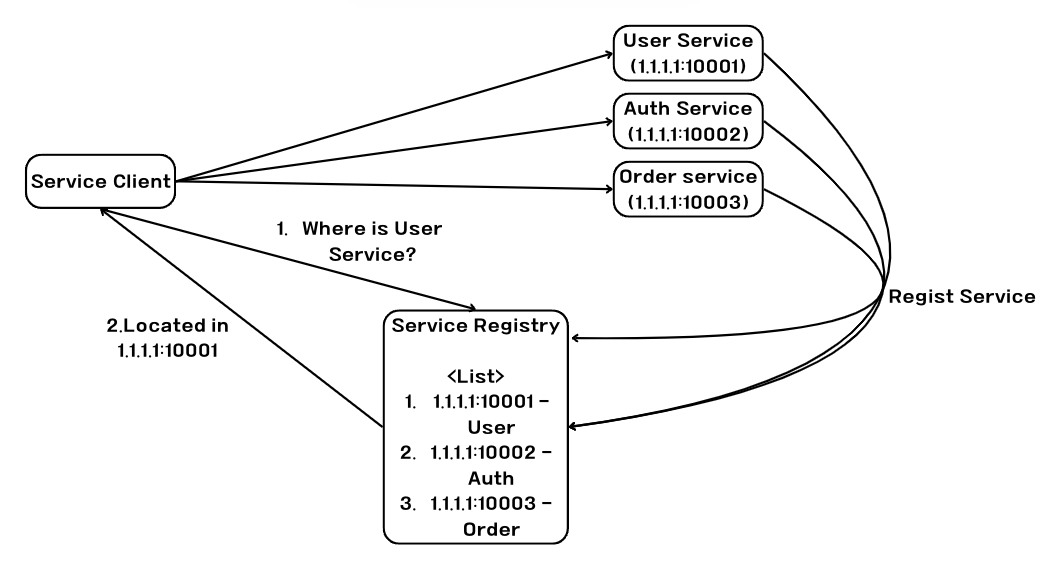
해당 서비스의 위치(IP, Port 등)를 저장하고 리스트를 관리하여 서비스를 호출하는 입장에서는 서비스의 위치를 몰라도 언제든지 서비스 디스커버리를 사용하여 요청을 전달할 수 있는 것이다.
서비스 디스커버리 전략 (서버 사이드 디스커버리/ 클라이언트 사이드 디스커버리)
이 두 전략의 차이는 다른 서비스를 호출할 때 Service Registry를 통해서 다른 서비스를 호출하는 유무이다.
MSA의 분산 환경에서는 서비스 간 원격 호출을 통해 데이터를 주고 받는데 이에 대한 주소를 Service Registry에 저장하게 된다.
두 전략의 차이를 그림을 통해 알아보자.
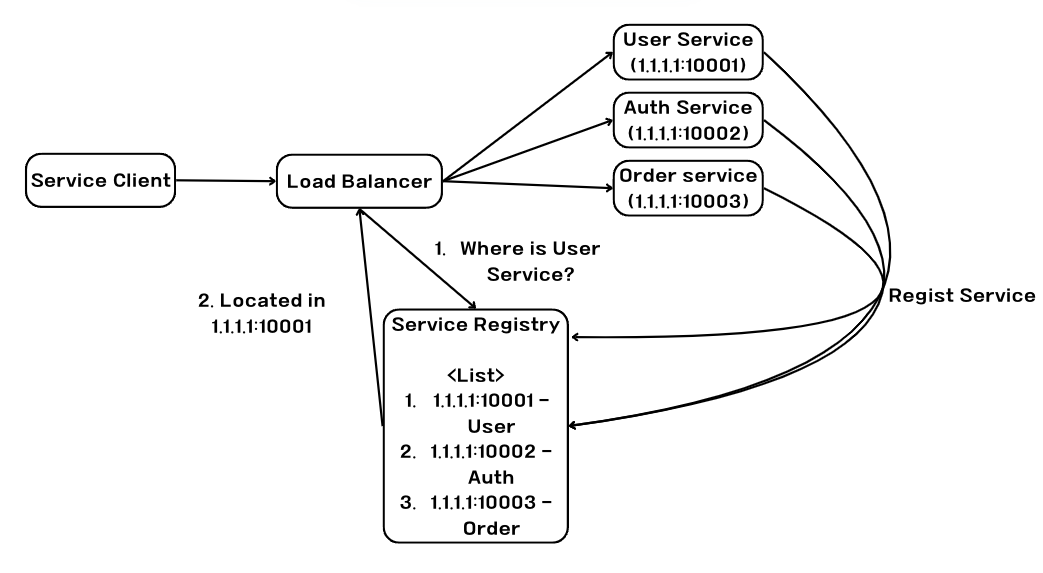
이미지만 보아도 확실히 알 수있을 것이다! 서버 사이드 디스커버리는 서비스 앞단에 proxy 서버와 같이 로드밸런서를 넣고 해당 로드밸런서에게 질의를 하여 라우팅이 되는 방식이다. 반면에 클라이언트 사이드 디스커버리는 Service Client가 직접 주소 질의에 대한 라우팅을 수행한다.
이때 Service Client의 구현체가 Netflix Eureka이다.
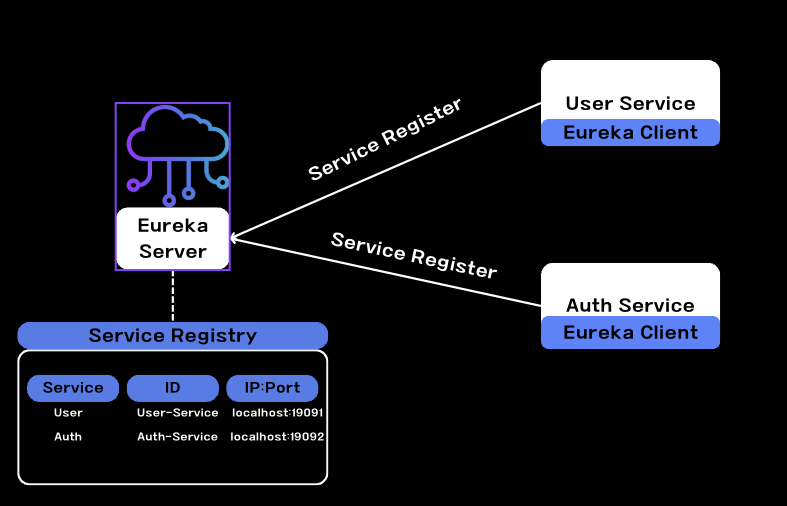
Spring Cloud Netflix Eureka
Eureka는 위에서 봤다시피 클라이언트 사이드 디스커버리 전략을 사용하여, 애플리케이션 코드 단에서 서비스 디스커버리 패턴을 구현한다.
각 서비스들이 호출하려는 서비스의 위치를 알고 있기 때문에 서비스별로 특성에 맞게 로드밸런싱 방식을 구현할 수 있다.
하지만 여기엔 단점이 존재하는데 각 서비스가 Service Registry에 의존적이게 된다. Service Registry역할을 하는 Eureka Server가 죽게되면 모든 서비스가 마비되는 것이다.
또한 서비스 별로 다른 언어(Java, Python, C++등) 및 프레임워크(Django, Spring 등) 다양한 환경으로 서비스들을 구성하였다면 이를 폴리그랏(polyglot) 환경이라고 하는데 각 언어와 프레임워크별로 여러 번 구현해줘야 하는 일이 생긴다.
Eureka 사용해보기
각 Client는 Eureka Server에 자신의 정보를 등록하며 주기적으로 Eureka Server에게 다른 서비스들의 정보를 업데이트한다.
각 서비스 애플리케이션이 실행되면 자동으로 서비스 정보를 등록해주게 된다.
1. Dependency 설정
Eureka Server 설정을 위해서는 netflix-eureka-server 의존성을 주입해준다.
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}2. applicatoin.yml 설정
spring:
application:
name: discovery-server
server:
port: 19090
eureka:
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone : http://localhost:19090/eureka/
instance:
hostname: localhost
server:
#기본 5분 : 클라이언트 서버와 유레카 서버 초기화 시간
# 기본 단위 ms
wait-time-in-ms-when-sync-empty: 3- spring.applicatoin.name : 해당 애플리케이션의 이름을 지정해주며 이 이름으로 registy에 저장된다.
- Server.port : 해당 포트번호로 registry에 저장된다.
- eureka.client.register-with-eureka : Eureka Server로 자신의 정보를 등록할지 결정한다. 굳이 그럴 필요는 없기 때문에 false로 설정
- eureka.client.fetch-registry : 다른 서비스들의 정보를 Eureka Server로부터 받아서 로컬 메모리에 캐싱여부. 현재 Eureka Server 설정이기에 캐싱할 필요가 없으므로 false! 불필요한 네트워크 트래픽을 방지할 수 있는 장점도 있다.
- eureka.client.service-url.defaultZone : Eureka Server의 URL을 지정한다. 이때 defaultZone은 꼭 카멜 케이스를 써준다. 스네이크 케이스를 쓰는경우 SpringBoot에서는 자동으로 카멜케이스로 변경해주는 경우도 있지만 해당 정보는 Map<String,String>타입으로 선언되어 있어 자동 변환이 수행되지 않는다.
- instance.hostname : 현재는 local로 진행되기에 localhost로 설정한다.
- eureka.server.wait-time-in-ms-when-sync-empty : 각 Service들을 등록하기 위한 초기화 시간이다. 기본값은 5분으로 되어 있으며 기본 단위는 ms이다.
3. EurekaServer 적용
@SpringBootApplication
@EnableEurekaServer
public class MovieReservationServerApplication {
public static void main(String[] args) {
SpringApplication.run(MovieReservationServerApplication.class, args);
}
}@EnableEurekaServer라는 어노테이션만 달아줘도 스프링의 강력한 기능인 PSA 덕분에 EurekaServer로 인식된다.
이렇게 설정을 마치고 잘 동작하는지 확인하기 위해 실행시키고 localhost:[내가정한 서버포트]로 브라우저에서 접속해보자
가운데 빨간 경고는 threshold와 renews 계산 값에 대한 경고표시인데 이후에 별도의 설정을 해줘야하는 걸로 보인다. 지금은 무시해도 된다!
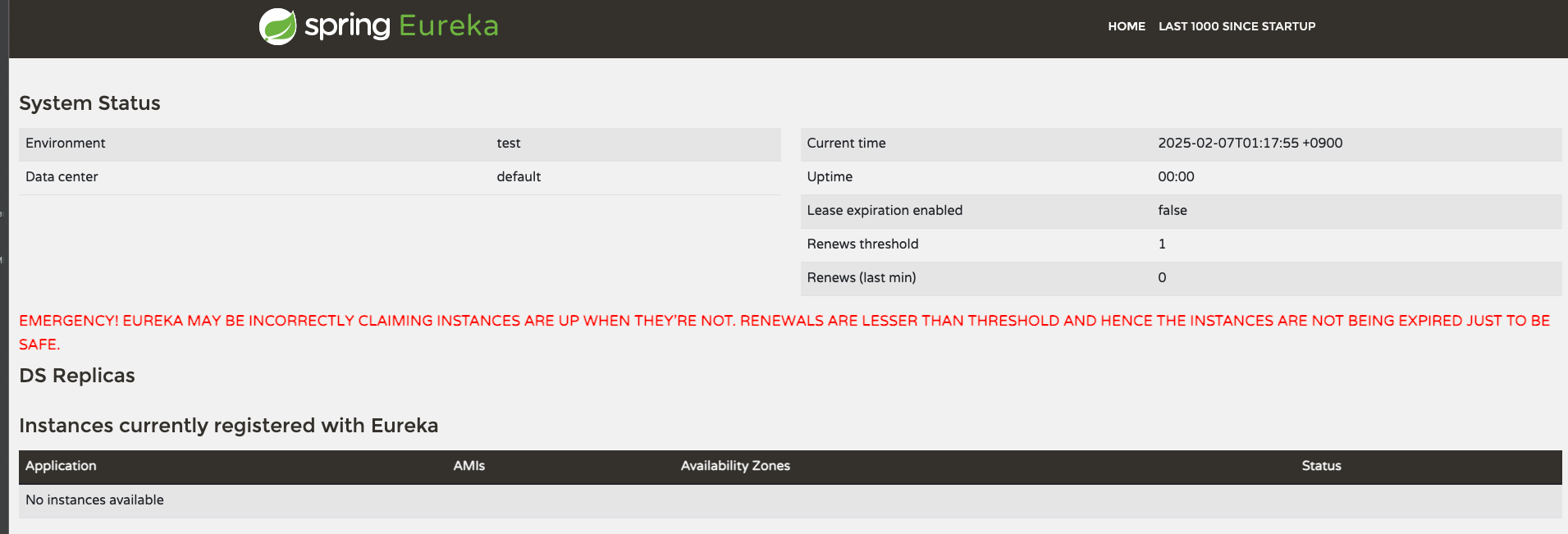
이후 생성하는 클라이언트 인스턴스는 Instances currently registered with Eureka라는 항목에 뜨게된다.
다음 포스팅에는 User라는 클라이언트를 하나 만들어서 연결하고 동작이 잘 되는지 통신을 해보도록 하겠다!
'Spring > Spring Cloud' 카테고리의 다른 글
| [MSA - Resilienc4j] CircuitBreaker, fallback 메서드 개발하기 (0) | 2025.02.11 |
|---|---|
| [MSA - Spring Cloud] Spring Cloud Gateway 개발하기 (1) | 2025.02.08 |
| [MSA] 멀티 모듈에서 중복되는 코드를 서브모듈끼리 공유하는 방법 (0) | 2025.02.08 |
| [MSA - Spring Cloud] Eureka Client 개발하기(feat. FeignClient) (0) | 2025.02.07 |
| [MSA] 모노 레포와 멀티 레포 전략 (0) | 2025.02.07 |