728x90
반응형
SMALL
Redis의 이해
- 대규모 서비스를 운영하기 위해서는 데이터를 안전하게 그리고 빠르게 저장하고 불러오는 기술이 필요하다.
- Redis는 In-Memory 데이터베이스이다. 모든 데이터를 메모리에 저장하고 조회한다.
- 기존 RDB보다 빠른 이유는 메모리 접근이 디스크 접근보다 빠르기 때문이다.
- Redis는 캐싱 솔류선, NoSQL, Key-Value저장소라고 부르기도 한다
Redis의 주요 특성
- Key-Value 스토어
- Key-Value 저장 방식의 스토리지 지원
- 컬렉션을 지원
- List, Set, Sorted Set, Hash 등의 자료구조를 지원
- Pub/Sub 지원
- Publisher,Subscriber 모델을 지원
- 디스크 저장(Persistent Layer)
- 현재 메모리의 상태를 디스크로 저장할 수 있는 기능
- 현재까지의 업데이트 내용을 로그로 저장할 수 잇는 AOF기능
- 복제
- 다른 노드에서 해당 내용을 복제할 수 있는 Master/Slave 구조를 지원
- 빠른 속도
- 이상의 기능을 지원하면서도 초당 100,000QPS(Queires Per Second) 수준의 높은 성능을 지원
Redis의 자료구조
- String
- 키와 연결할 수 있는 가장 간단한 유형의 값
> set hello world OK > get hello "world"- String타입에는 모든 종류의 문자열을 저장할 수 있다. 따라서 JPEG이미지, HTML fragment를 캐시하는 용도로 자주 사용한다. 최대 저장 사이즈는512MB이다.
- 아래와 같은 다양한 기능도 제공한다.
- string을 정수로 파싱하고, 이를 atomic하게 증감하는 커맨드
> set counter 100 OK > incr counter (integer) 101 > incr counter (integer) 102 > incrby counter 50 (integer) 152- 키를 새 값으로 변경하고 이전 값을 반환하는 커맨드
> INCR mycounter (integer) 1 > GETSET mycounter "0" "1" redis> GET mycounter "0"- 키가 이미 존재하거나, 존재하지 않을 때에만 데이터를 저장하게 하는 옵션
> set mykey newval nx (nil) > set mykey newval xx OK
- List
- list는 일반적인 linked List의 특징을 갖는다.
- 수백만 개의 아이템이 있더라도 head와 tail에 값을 추가할 때 동일한 시간이 소요된다. 특정 값을 인덱스로 데이터를 찾거나 삭제할 수 있다.
LPUSH mylist B # now the list is "B" LPUSH mylist A # now the list is “A","B" RPUSH mylist A # now the list is “A”,”B","A"- 여러 작업에 list가 쓰이지만, 대표적인 사용 사례는 Pub-Sub(생산자-소비자)패턴이다. 프로세스간 통신 방법에서 생산자가 아이템을 만들어서 list에 넣으면 소비자가 꺼내와서 수행하는 식으로 동작한다.
- 레디스는 이를 좀더 효율적이고 안정적으로 만들게 해준다.
- 또한 일시적으로 list를 blocking하는 기능도 유용하게 사용할 수 있다. Pub-Sub상황에서 list가 비어있을 때 pop을 시도하면 대개 null을 반환하게 되는데 이 경우 소비자는 일정시간을 기다린 후 다시 pop을 시도한다.(=polling)
- 레디스의 BRPOPO을 사용하면 새로운 아이템이 리스트에 추가되었을때에만 응답하므로 polling프로세스를 줄일 수 있다.
- Hash
- field-value쌍을 사용한 일반적인 해시
- key에대한 field의 개수는 제한이 없으므로 여러 방법으로 사용이 가능하다.
- field와 value의 구성은 RDB의 table과 비슷하다. hash key는 PK, field는 column, value는 value로 볼 수 있다.
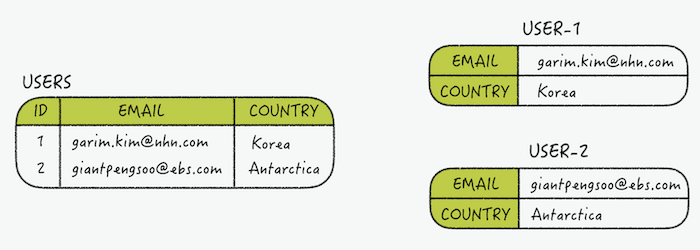
아래와 같이 개별 아이템을 atomic하게 조작할 수 있는 커맨드도 존재한다.> hmget user-2 email country 1) "giantpengsoo@ebs.com" 2) "Antarctica" > hincrby user:1000 birthyear 10 (integer) 1987 > hincrby user:1000 birthyear 10 (integer) 1997- meetup.nhncloud.com/posts/224
- Set
- 객체 간의 관계를 표현할 떄 사용한다.
- 예를 들어 태그기능이 있을 때. ID가 1000인 프로젝트에 1,2,5,77번을 연결한 경우 set에서 표현하는 방법은 간단하다.
- key값을 project:1000:tags 로 지정하고 여기에 태그를 모두 지정해준다.혹은 아래처럼 태그를 기준으로 저장할 수도 있습니다 (태그 -> ID 1을 갖고있는 -> 프로젝트). 1,2,10,27 태그를 가지고 있는 모든 프로젝트의 목록을 원할 때에는
SINTER커맨드로 간단하게 확인할 수 있습니다. > sadd tag:1:projects 1000 (integer) 1 > sadd tag:2:projects 1000 (integer) 1 > sadd tag:5:projects 1000 (integer) 1 > sadd tag:77:projects 1000 (integer) 1 > sinter tag:1:projects tag:2:projects tag:10:projects tag:27:projects 0) 1000 ...sadd project:1000:tags 1 2 5 77 (integer) 4 > smembers project:1000:tags 1. 5 2. 1 3. 77 4. 2
- Sorted Set
- set과 마찬가지로 key하나에 중복되지 않는 여러 멤버를 저장하지만, 각각의 멤버는 value에 연결된다.
- 모든 데이터는 해당 값으로 정렬되며, value가 같다면 멤버값의 사전 순서로 정렬된다.sorted set은 정렬된 형태로 저장되기 때문에 때문에 인덱스를 이용하여 빠르게 조회할 수 있습니다. (인덱스를 이용하여 조회할 일이 많다면 list보다는 sorted set의 사용을 권장합니다.)
> zrange birthyear 2 3
2) "WILLIAM"
3) "BENTLEY"
스코어를 이용한 조회도 물론 가능합니다. 위의 예제 그림에서 멤버값은 이름, 스코어는 태어난 년도입니다. 예를 들어 2000년대에 모든 멤버를 조회하고 싶을 때에는 아래처럼 ZRANGEBYSCORE 커맨드를 사용해서 2000년부터 ~ 끝까지(+inf) 로 검색할 수 있습니다.
> zrangebyscore birthyear 2000 +inf
1) "PENGSOO"
2) "WILLIAM"
3) "BENTLEY"
그 외에도..
- bit / bitmap:
SETBIT,GETBIT등의 커맨드로 일반적인 비트 연산이 가능합니다. 비트맵을 사용하면 공간을 크게 절약할 수 있다는 장점이 있는데요, 이 내용은 다음번 활용사례에서 자세하게 말씀드리겠습니다. - hyperloglogs: 집합의 카디널리티(원소의 갯수)를 추정하기 위한 데이터 구조입니다. (ex. 검색 엔진의 하루 검색어 수) 일반적으로 이를 계산할 때에는 데이터의 크기에 비례하는 메모리가 필요하지만, 레디스의 hyperloglogs를 사용하면 같은 데이터를 여러번 계산하지 않도록 과거의 항목을 기억하기 때문에 메모리를 효과적으로 줄일 수 있습니다. 메모리는 매우 적게 사용하고 오차는 적습니다.
- Geospatial indexes: 지구상 두 지점의 경도(longitude)와 위도(latitude)를 입력하고, 그 사이의 거리를 구하는 데에 사용됩니다. 내부적으로는 Sorted Set Data Structure를 사용합니다.
- Stream: 레디스 5.0에서 새로 도입된 로그를 처리하기 위해 최적화된 데이터 타입입니다. 차별화된 다양한 장점이 있지만, 가장 큰 특징은 소비자(Consumer)그룹을 지정할 수 있다는 것입니다. Stream에 대해서는 다음 기회에 더 자세하게 말씀드리겠습니다.
Redis Key
- 키는 문자열이기 떄문에 ‘abc’부터 JPEG 파일까지 모든 이진 시퀀스를 키로 사용할 수 있다.
- 빈 문자열도 키가 될 수 있다. 마찬가지로 최대 크기는 512MB이다.
- 키를 너무 길게 사용하는 것은 권장하지 않는다 조회할때 비용이 많이 드릭 떄문이다.
- 만약 긴 이름의 키를 저장해야 한다면 hash의 member로 저장하는것이 더 좋은 방법이다.
- 그렇다고 해서 가독성이 좋은 ‘user:1000:followers’를 u1000flw로 줄이는건 크게의미가 없다.
- 보통 스키마를 사용해서 레디스의 키를 설계하는 것이 좋으며 object-type:id의 형태를 권장한다.
- comment:reply.to또는 comment:reply-to와 같이 . - : 등의 부호를 사용해서 관계를 나타낼 수도 있다.
- 키에 대한 커맨드는 데이터 타입에 국한되지 않고 사용할 수 있다.
SORT는 입력된 키에 해당하는 아이템을 정렬되어 보여준다. - list, set, sorted set에 사용할 수 있고, 특히 기존에 정렬되지 않은 상태로 저장된 set을 해당 커맨드를 사용해서 정렬시켜 보여줄 수 있다.
EXISTS커맨드는 해당 키가 레디스에 있는지 확인하고,DEL커맨드는 값에 관계없이 키를 삭제한다.TYPE커맨드는 해당 키에 연결된 자료구조가 어떤 형태인지 반환한다.
Expire기능
- 레디스는 In-Memory DB인 만큼, 메모리에 저장될 수 있는 데이터는 한정적이다. 더이상 메모리에 데이터를 저장할 수 없는 경우 레디스에서는 가장 먼저 들어온 데이터를 삭제하거나, 가장 최근에 사용되지 않은 데이터를 삭제하거나, 혹은 더이상 데이터를 받지 못하게 한다.
- 가장 좋은 방법은 데이터를 레디스에게 맡기지 않고, 직접 설정하는 것이다. 해당 데이터를 입력할 때 이 데이터의 사용 기한이 언제까지인지를 직접 설정해줌으로서, 어플리케이션이 직접 데이터의 만료 시간을 설정할 수 있다.
캐시로써의 레디스
- Look Aside(=Lazy Loading)
- 어플리케이션에서 데이터를 가져올때 레디스에 항상 먼저 요청하고, 데이터가 캐시에 있을때에는 레디스에서 데이터를 반환한다.
- 데이터가 캐시에 없을 경우 어플리케이션에서 데이터베이스에 데이터를 요청하고, 어플리케이션은 이 데이터를 다시 레디스에 저장한다.
- 해당 구조를 사용하면 실제 사용되는 데이터만 캐시할 수 있고, 레디스의 장애가 어플리케이션에 치명적인 영향을 주지 안흔다는 장점이 있다.
- 하지만 캐시에 없는 데이터를 쿼리할 떄 더 오랜 시간이 걸리는 단점과, 캐시가 최신 데이터를 가족 있다는 보장을 하지 못하는 단점이 있다. 캐시에 해당 key값이 존재하지 않을 때에만 캐시에 대한업데이트가 일어나기 때문에 데이터베이스에서 데이터가 변경될때에는 해당 값을 캐시가 알지 못하기 때문이다.
Write - Through
- Write-Through 구조는 DB에 데이터를 작성할 때마다 캐시에 데이터를 추가하거나 업데이트한다. 이로인해 캐시의 데이터는 항상 최신 상태를 유지할 수 있지만, 데이터 입력 시 두 번의 과정을 거쳐야 하기 때문에 지연 시간이 증가한다는 단점이 존재한다. 또한 사용되지 않을 수도 잇는 데이터도 일단 캐시에 저장하기 때문에 리소스 낭비가 발생한다.
- 이를 해결하기 위해 데이터 입력 시 TTL을 꼭 사용하여 사용되지 않는 데이터를 삭제하는 것을 권장한다.
Redis활용 사례
- 좋아요 처리하기
- 하나의 댓글에 한 번만 좋아요를 할 수 있도록 제한하는 것이 중요하다.
- RDBMS에서는 유니크 조건을 생성하여 처리할 수 있따.
- 하지만 많은 입력을 받는 환경에서 RDBMS를 사용한다면 insert와 update에 의한 성능 저하가 필연적으로 ㅂ라생하게 된다.
- Redis의 Set을 이용하면 이 기능을 간단하게 구현할 수 있으며, 빠른 시간 안에 처리할 수 있따.
- set은 순서가 없고, 중복을 허용하지 않는 집합이므로 댓글의 번호를 사용해서 key를 생성하고, 해당 댓글에 좋아요를 누른 사용자의 ID를 아이템으로 추가하면 동일한 ID값을 저장할 수 없으므로 한 명의 사용자는 하나의 댓글에 한 번만 좋아요를 누를 수 있게 된다.
- 최근 검색 목록 표시하기
- 최근 검색된 내역을 조회하는 것도 레디스로 간단하게 구현이 가능하다.
- RDBMS에서 테이블을 이용해서 조회를 한다면 아래처럼 쿼리를 만들 수 있다.
select * from KEYWORD where ID = 123 order by reg_date desc limit 5;- 이 쿼리는 테이블을 이용하므로 중복 제거도 해야 하고, 멤버별 저장된 데이터의 개수도 확인해야하며, 오래된 검색어는 삭제해야하는 번거로움이 있다. 애초에 중복을 허용하지 않고, 정렬되어 저장되는 레디스의 sorted set을 사용하면 간단하게 구현할 수 있다.
- sorted set은 가중치를 기준으로 오름차순 되기 떄문에 가중치로 시간을 사용한다면 이 값이 가장 큰, 나중에 입력된 아이템이 맨 마지막 인덱스에 저장된다.
- 멤버 ID가 123인 사람이 최근 검색한 사람은 위 그림처럼 정렬되어 저장됩니다. 이때 가중치는 입력 순간의 나노세컨드이고, 가장 처음 검색한 사람의 ID는 46, 가장 마지막 검색한 사람은 50입니다. 이 때 ID가 51인 사람을 검색하면 아래처럼 마지막에 데이터가 추가된다.
- 항상 다섯명만 저장하기 위해서는 인덱스가 0인 아이템을 지우면 됩니다. 하지만 아이템 개수가 6보다 작을 때에는 0번째 인덱스를 삭제하면 안되기 때문에 매번 아이템의 수를 먼저 확인해야 하는 번거로움이 있다. 이 때 sorted set의 음수 인덱스를 사용한다면 더 간단해집니다. 음수 인덱스는 인덱스의 마지막부터 큰 값부터 작은 값으로 매겨지는데요, 아래 그림과 같다.
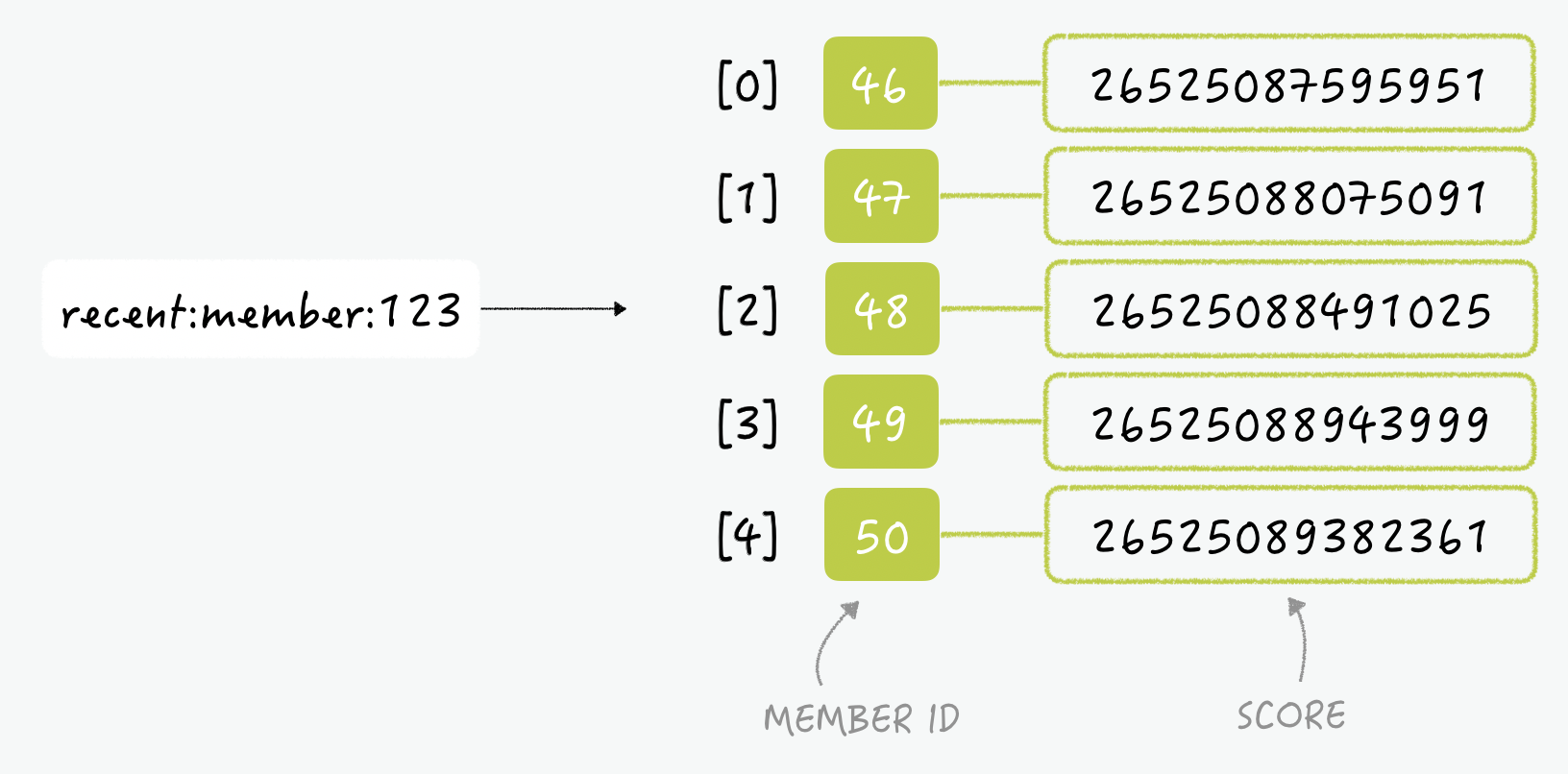


> ZREMRANGEBYRANK recent:member:123 -6 -6
- 데이터에 멤버를 추가한 뒤, 항상 -6번째 아이템을 지운다면 특정 개수 이상의 데이터가 저장되는 것을 방지 할 수 있게 됩니다. 인덱스로 아이템을 지우려면 ZREMRANGEBYRANK 커맨드를 사용하면 간단합니다. 이렇게 레디스의 sorted set을 이용하면 많은 공수를 들이지 않고도 최근 검색한 담당자를 보여줄 수 있는 기능을 구현할 수 있게 된다.
Redis와 Memcahed 비교
- MemCached는 캐싱 솔루션이며 Redis는 거기에 저장소의 개념까지 추가된 것
- 캐싱이란 말은 빠른 응답을 위해 결과를 보장해주는 솔루션이며 언제 사라져도 상관없다
- 저장소의 개념은 데이터가 보존되어야 한다는 말을 뜻한다
- 그래서 Redis는 RDB나 AOF 기능을 지원하기도 한다
Redis 와 Memcached 의 장단점 비교
| 기능 | Redis | Memcached |
|---|---|---|
| 속도 | 초당 100,000 QPS 이상 | 초당 100,000 QPS 이상 |
| 자료구조 | List, Set, Sorted Set, Hash 지원 | Key-Value 만 지원 |
| 안정성 | 특성을 잘못 이해할 경우에 장애가 발생할 수 있다. | 장애가 거의 없다. |
| 응답 속도의 균일성 | Memcached 에 비해서 응답속도의 균일성이 떨어질 수 있다. | 전체적으로 응답속도는 균일하다. |
| - 응다 속도나 균일성 같은 경우가 차이나는 이유는 메모리 할당 구조가 다르기 떄문인데 Redis는 Jemalloc()을 사용해 메모리 할당을 하고 free()를 통해서 메모리 할당을 지운다. | ||
| - Memcached는 slab을 통해서 일정한 사이즈의 메모리를 균ㅇ리하게 1MB의 페이지로 자르고 그 안에 또 작은 사이즈 부터 큰 사이즈의 chunk()를 일정하게 놔두는 식을 이용해 메모리 내부 단편화 현상은 있지만 외부 단편화는 없도록 해서 메모리 관리를 조금 더 효율적으로 이요할 수 있어 비교적 균일하다. |
Redis의 운영과 관리
- Redis는 싱글 스레드다
- 의도하지 않게 성능이 안나오거나 장애가 발생할 수 있는 경우가 발생하는데 Redis가 싱글 스레드이기 때문이다.
- 서버에서
Keys명령을 사용하지 말자.- 이 명령을 사용하면 모든 key를 검색해서 사용하기 때문에 데이터가 적다면 별 문제없겠지만 몇백만개, 몇 천만개가 넘어가면 많은 시간을 소모하게 된다.
- Flsushall/flushdb 명령을 주의하자
- Memcached의 flushall과는 다르게 Redis의 flushall은 지우는데 keys명령와 같이 많은 시간이 할애된다.
Redis Persistent
- Redis와 Memcached를 구분하는 특성 중에 하나는 redis의 데이터를 디스크로 저장할 수 있는 Persistent 기능을 제공한다.
- Memcache의 경우 서버가 장애를 일으키는 경우 restart하면 모든 데이터가 사라지지만 Redis는 디스크에 저장된 데이터를 기반으로 다시 복구하는게 가능하다.
- 이런 Persistent 기능은 데이터 스토어로서의 장점이 있지만 이 기능 떄문에 장애의 주 원인이 될 수도 있다.
- 장애가 발생할 수 있는 RDB, AOF 등의 기능에 대해 알아보자
RDB
- RDB는 RDBMS와 다르다. RDB는 단순히 메모리의 스냅샷을 파일 형태로 저장할 떄 쓰이는 파일의 확장자명이다.
- RDB를 사용해 현재 메모리에 대한 스냅샷을 만든다면 Redis에서는 싱글 스레드 기반으로 많은 시간이 걸릴 수 있다고 생각한다. RDB를 하는 방식은 SAVE,BGSAVE 두가지 방식이 있다.
- SAVE방식은 모든 작업을 멈추고 현재 메모리 상태에 대한 RDB파일을 생성한다.
- BGSAVE는 백그라운드 SAVE라는 의미로 fork() 명령을 통해서 부모 프로세스로부터 자식 프로세스를 생성하고 현재 가지고 있는 메모리의 상태가 복제된 상태에서 데이터를 저장하도록 한다.
- RDB를 사용하려면 redis.conf파일에 다음과 같은 내용을 추가한다.
dbfilename dump.rdb- 기본적으로 REdis에서는 RDB사용 옵션이 설정되어 있고 save명령에 따라 실행이 가능하다.
- 실행되는 명령은 save 이런 구조로 사용하고 save 900 10이렇게 사용한다.
- 900초 안에 10번의 변경이 있을떄 스냅샷을 저장한다는 뜻이다.
AOF
- Append Only File의 약어로 데이터를 저장하기 전에 AOF 파일에 현재 수행할 명령어를 저장해놓고 장애가 발생하면 AOF기반으로 복구한다.
- 다음과 같은 순서로 데이터가 저장된다.
- 클라이언트가 Redis에 업데이트 관련 명령을 요청
- REdis는 해당 명령을 AOF에 저장
- 파일쓰기가 완료되면 실제로 해당 명령을 수행해서 Redis메모리에 내용을 변경
- AOF는 Redis설정 파일인 redis.conf에 기본적으로 사용되지 않으므로 직접 변경을 해줘야 한다.
# appendonly 는 기본적으로 no 로 설정되어 있다. appendonly yes appendfilename appendonly.aof appenfdsync everysec- 주의해야 할 점은 appendfdsync값이다. AOF는 파일에 저장할 떄 파일을 버퍼 캐시에 저장하고 적절한 시점에 이 데이터를 디스크로 저장하는데 appendfsync는 디스크와 동기화를 얼마나 자주 할 것이지에 대해 설정하는 값으로 3가지로 정할 수 있다.
- always : AOF값을 추가할때마다 fsync를 호출해서 디스크에 실제 쓰기
- everysec : 매초마다 fsync를 호출해서 디스크에 실제 쓰기
- no: OS가 실제 sync를 할 때까지
AOF와 RDB의 우선순위
- RDB는 주기적으로 스냅샷을 띄우므로 최신의 데이터를 가지진 못하지만 AOF는 메모리에 수정사항을 반영하기 전에 항상 디스크에 추가하기 떄문에 둘 다 있다면 AOF를 기준으로 읽는다.
Redis가 Memory를 두배로 사용하는 문제
- 가장 큰 원인은 RDB를 저장하는 Persisntent기능으로 BGSAVE 방식에서 fork()를 사용하기 때문이다.
- 현대 운영체제에서 fork()를 사용해서 자식 프로세스를 생성하면 COW(Copy on Write)라는 기술을 사용해서 부모 프로세스의 메모리에서 실제 변경이 필요한 부분을 복사한다.
- 그러므로 해당 부분이 두 개가 존재하게 되는데 이때 메모리를 두배로 사용할 수 밖에 없다.
- Redis를 사용할 떄 실제 Physical메모리를 모두 사용하지 말고 약간의 여분을 두고 RDB를 사용하는 경우를 생각해두는게 좋다.
Redis의 복제
- DBMS가 제공하는 것과 같이 복제기능을 제공한다.
- Mast/Slave 형태의 복제 모델을 지원한다. 이를 통해서 Master의 변경은 Slave를 타고 전파된다.
- 그리고 Slave는 오로지 한 대의 Master만 가질 수 있다는 것을 기억해두자.
- 그리고 Slave가 다른 장비의 Master가 될 수도 있다.
참고 블로그
개발자를 위한 레디스 튜토리얼 03 : NHN Cloud Meetup
개발자를 위한 레디스 튜토리얼 03 : NHN Cloud Meetup
지금부터는 레디스의 `HA`(High Availability)에 대해서 알아보겠습니다. 레디스는 **Master - Replica** 형태의 복제를 제공합니다.
meetup.nhncloud.com
Redis 를 실무에 사용하기 전 꼭 알아야 하는 전략
Redis 를 실무에 사용하기 전 꼭 알아야 하는 전략
Redis를 실무에 사용하기 전에 꼭 알아야 하는 내용에 대해 정리한 글입니다. 정리한 내용은 다음과 같습니다.Redis 의 이해Redis 운영과 관리Redis 복제Reference: Redis 운영 관리대규모 서비스를 운영하
velog.io
728x90
반응형
SMALL
'Redis > Redis 개념' 카테고리의 다른 글
| Trie와 Redis ZSET 비교: 키워드 자동완성 기능에 가장 효율적인 방법은? (2) | 2024.12.17 |
|---|---|
| [Spring/Redis] Redis 문서 정리(Search With Redis) (0) | 2024.06.11 |
| [Spring/Redis] Redis 문서 정리(User Roles, Secondary Indexes) (0) | 2024.06.11 |
| [Spring/Redis] Redis문서 정리(Object Mapping & Redis Repository) (0) | 2024.06.11 |
| [Spring/Redis] Redis문서정리(Redis Spring 시작하기) (0) | 2024.06.11 |