자바 특징,환경,연산,제어문
Java의 특징
➕ Java는 객체지향 프로그래밍 언어입니다.
기본 자료형을 제외한 모든 요소들이 객체로 표현되고, 객체 지향 개념의 특징인 캡슐화, 상속, 다형성이 잘 적용된 언어입니다.
장점
JVM(자바가상머신) 위에서 동작하기 때문에 운영체제에 독립적이다.
GabageCollector를 통한 자동적인 메모리 관리가 가능하다.
단점
JVM 위에서 동작하기 때문에 실행 속도가 상대적으로 느리다.
다중 상속이나 타입에 엄격하며, 제약이 많다.
Java8에서 새롭게 추가된 기능을 말씀해주세요.
- 인터페이스에 디폴트 메소드와 정적 메소드 추가
- 함수형 인터페이스, 람다 표현식, 메소드 참조 기능 추가
- 스트림 API 도입
- 새로운 날짜 관련 라이브러리 추가
- Optional 지원
- 병렬 처리 지원
Java11에 새로 추가된 기능을 설명해주세요.
- String에 새로운 메소드 추가
- Files 클래스에 새로운 메소드 추가
- 컬렉션 인터페이스에 새로운 메소드 추가
- Predicate 인터페이스에 새로운 메소드 추가
- 람다에서 로컬 변수 Var 사용
- 자바 파일 실행 방식 단순화
JVM이란?
➕
자바 가상 머신의 약자를 따서 줄여 부르는 용어로 JVM의 역할은 운영체제의 독립적으로 자바를 실행하는 것입니다.
JVM의 구조
Class Loader : JVM 내(Runtime Data Area)로 Class 파일을 로드하고 링크
Execution Engine : 메모리(Runtime Data Area)에 적재된 클래스들을 기계어로 변경해 실행
Garbage Collector : 힙 메모리에서 참조되지 않는 개체들 제거
Runtime Data Area : 자바 프로그램을 실행할 때, 데이터를 저장
자바의 컴파일 과정
➕ 자바로 개발된 프로그램을 실행하면 JVM은 OS로부터 메모리를 할당합니다.
- 자바 컴파일러(javac)가 자바 소스코드(.java)를 자바 바이트코드(.class)로 컴파일합니다.
- Class Loader를 통해 JVM Runtime Data Area로 로딩합니다.
- Runtime Data Area에 로딩 된 .class들은 Execution Engine을 통해 해석합니다.
- 해석된 바이트 코드는 Runtime Data Area의 각 영역에 배치되어 수행하며 이 과정에서 Execution Engine에 의해 GC의 작동과 스레드 동기화가 이루어집니다.

JDK와 JRE의 차이점
➕ JDK(Java Development Kit)는 Java 개발을 위해 필요한 도구들의 집합입니다.
컴파일러, 디버거, 개발 도구 등을 포함하고 있습니다.
JRE(Java Runtime Environment)는 Java 애플리케이션을 실행하기 위한 런타임 환경입니다.
JVM(Java Virtual Machine), 클래스 라이브러리, 실행환경 등을 포함하고 있습니다.
JDK는 JRE를 포함하고 있으므로, JDK는 개발자용으로 JRE를 포함한 모든 도구를 제공합니다.
GC에 대해 설명해주세요.
➕ 가비지 컬렉션은 JVM의 메모리 관리 기법 중 하나로 시스템에서 동적으로 할당됐던 메모리 영역 중에서 필요없어진 메모리 영역을 회수하여 메모리를 관리해주는 기법입니다.
GC의 작업을 수행하기 위해 JVM이 어플리케이션의 실행을 잠시 멈추고, GC를 실행하는 쓰레드를 제외한 모든 쓰레드들의 작업을 중단 후 (Stop The World 과정) 사용하지 않는 메모리를 제거(Mark and Sweep 과정)하고 작업이 재개됩니다
.++ GC의 작업은 Young 영역에 대한 Minor GC와 Old 영역에 대한 Major GC로 구분됩니다.
▶ 꼬리질문 - GC의 필요성에 대해 말씀해주세요.
Java Runtime시 Heap 영역에 저장되는 객체들은 따로 정리하지 않으면 계속해서 메모리에 쌓이게되어 OutOfMemmory Exception이 발생합니다.
WAS 같은 경우 WAS가 다운될 수가 있는데 이를 방지하기 위하여 JVM에서는 주기적으로 사용하지 않는 객체를 수집하여 정리해주어야합니다. 이 역할을 하는게 GC입니다.
▶ 꼬리질문 - GC의 장단점은 어떤 게 있을까요?
장점
- 메모리를 수동으로 관리하던 것에서 비롯된 에러를 예방할 수 있다.
- 개발자의 실수로 인한 메모리 누수
- 해제된 메모리를 또 해제하는 이중 해제
- 해제된 메모리에 접근
단점
- GC의 메모리 해제 타이밍을 개발자가 정확히 알기 어렵다.
- 어떠한 메모리 영역이 해제의 대상이 될 지 검사하고, 실제로 해제하는 일이 모두 오버헤드다.
자바의 메모리 영역에 대해 설명해주세요.
➕
- Method Area
- 클래스가 로딩될 때 할당된다.
- 패키지, 클래스, 인터페이스, 생성자, 메소드, 필드, Static 변수 등을 저장한다.
- 모든 스레드가 공유한다.
- Heap Area
- 런타임 시에 동적으로 할당된다.
- new 키워드로 생성된 객체와 배열이 저장되는 영역이다.
- Heap 영역에 생성된 객체와 배열은 Stack 영역의 변수에서 참조한다.
- Garbage Collector가 참조하지 않는 메모리를 제거한다.
- Stack Area
- 스레드마다 존재하며, 스레드가 시작될 때 할당된다.
- 지역변수, 파라미터, 리턴값, 연산에 사용되는 값 등이 생성되는 영역이다.
- 메소드를 호출할 때마다 개별적으로 스택이 생성되며 종료시 해제된다.
- 선입후출의 구조를 가진다.
- 기본 타입 변수는 Stack 영역에 직접 값을 가진다.
- 참조 타입 변수는 Method 영역이나 Heap 영역의 참조 주소를 가진다.
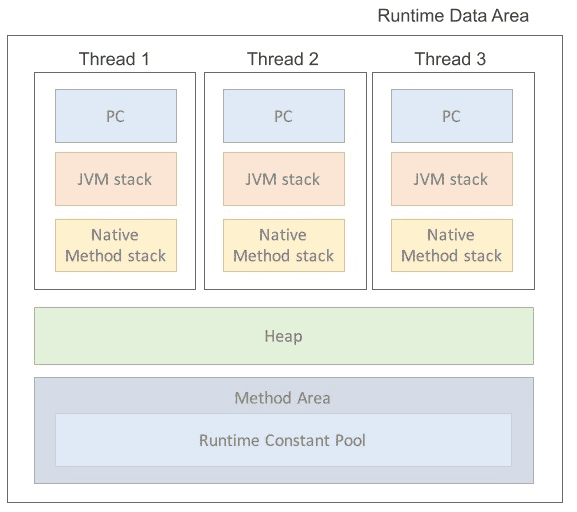
Runtime Data Area
Java에서 제공하는 원시 타입들에 무엇이 있고, 각각 몇 바이트를 차지하나요?
➕
- byte — -128에서 127 사이의 정수, 용량은 1바이트입니다.
- short — -32768에서 32767 범위의 정수, 용량은 2바이트입니다.
- int — 정수 -2147483648 ~ 2147483647, 용량은 4바이트입니다.
- long — 9223372036854775808 ~ 9223372036854775807 범위의 정수, 용량은 8바이트입니다.
- float — -3.4E+38 ~ 3.4E+38 범위의 부동 소수점 숫자, 용량은 4바이트입니다.
- double — -1.7E+308에서 1.7E+308 범위의 부동 소수점 숫자, 용량은 8바이트입니다.
- char — UTF-16의 단일 문자, 용량은 2바이트입니다.
- Boolean — true/false , 용량은 1바이트입니다.
꼬리질문 - 원시 타입과 참조 타입의 차이를 설명해주세요.
- 성능 관점
- 원시 타입은 스택 영역에 존재한다. 반면 참조 타입은 스택 영역에는 참조 값만 있고, 실제 값은 힙 영역에 존재한다. 참조 타입은 최소 2번 메모리 접근을 해야 하고, 일부 타입의 경우 값을 필요로 할 때 언박싱 과정(ex. Double → double, Integer → int)을 거쳐야 하므로
- 원시 타입과 비교해서 접근 속도가 느린 편이다.
- 메모리 관점
- 원시 타입보다
- 참조 타입이 사용하는 메모리 양이 압도적으로 높다.
- NULL 관점
- 원시 타입은 null을 담을 수 없지만, 이것은 원시 타입의 경우, 값이 없으면 디폴트 값을 반환하기 때문이다. (ex. int은 0, boolean은 false)
- 참조 타입은 null을 담을 수 있다.
- 제네릭 관점
- 원시 타입은 제네릭 타입에서 사용할 수 없지만,
- 참조 타입은 가능하다.
==와 equals의 차이점은?
➕ ==는 두 객체의 참조(메모리 주소)를 비교하는 연산자입니다.두 객체의 참조가 동일한 경우에만 true를 반환합니다.equals() 메서드는 객체들 간의 내용적인 동등성을 비교하는 메서드입니다.즉, 두 객체의 값이 동일한 경우에 true를 반환합니다. equals() 메서드는 객체의 클래스에 따라 재정의할 수 있습니다.
부동소수점과 고정소수점 방식의 차이에 대해 설명하세요
➕ float는 가수부(23bit)와 지수부(8bit)로 나뉜다. 나머지 1비트는 부호를 표기하기 위한 공간입니다.
double은 11bit의 지수부와 52bit의 기수부가 존재합니다.
고정 소수점은 메모리를 정수부와 소수부로 고정으로 나누어 지정하고 처리합니다.
개념
- 말 그대로, 소수점이 찍힐 위치를 미리 정해놓고 소수를 표현하는 방식입니다.
- 보통 실수는 정수 + 소수로 표현합니다.
예시
- 예를 들어, -3.14라는 소수를 표현하기 위해서는 다음의 세 가지 요소가 필요로합니다.
1) 음수와 양수를 나타내줄 부호 (-)
2) 정수부 (3)
3) 소수부 (0.14)
장점?
- 실수를 정수부와 소수부로 분할표현해서 비교적 단순합니다.
단점?
- 너무 단순해서 치밀하지도 않고, 효율적이지도 못합니다.
- 정수부는 15bit, 소수부는 16bit로 자리수가 그다지 크지 않기 때문에, 표현의 범위가 생각보다 넓지 않습니다.
- 이 방식으로는 간단한 성적 처리 조차도 힘겹기 때문에 잘 사용되지 않습니다.
직관적으로 보여줄 수 있습니다.
고정 소수점을 쓴다면, 16비트 이하의 수는 반영되지 못하는 문제가 생기게 된다.
그래서 이를 보완하고자 존재하는 것이 바로 부동 소수점이다.
오버스택플로우의 정수/실수 에 대해 설명해보세요
➕ 정수부의 오버스택 플로우는 해당 타입이 담을 수 있는 메모리 공간을 초과하는 경우 예외가 발생합니다.
실수부의 오버스택, 언더스택플로우는 해당 타입이 담을 수 있는 메모리 공간을 초과하는 경우 오버스택플로우는 무한대, 언더플로우시 양의 최소값보다 작은 값으로 0이 됩니다.
상수풀(Constant Pool)이란?
➕ 모든 객체는 new로 생성해야하는 반면 String은 new 없이 리터럴("")만으로 객체를 생성할 수 있는 특수한 클래스입니다.
constant pool은 해시테이블 구조로 되어 있어 동일한 문자열은 해시테이블 상 같은 키를 갖게 되어 동일한 주소를 갖게 됩니다.
equals()는 문자열을 비교하기 때문에 같은 문자열에 대해서는 true가 나오지만 일반 객체처럼 String 객체를 Heap에 생성시킨다면 리터럴로 저장된 String 객체와의 주소값이 다르게 설정됩니다.
리터럴로 선언할 시 내부적으로 intern() 메서드가 실행되어 주어진 문자열이 String Constant Pool에 존재하는지 검색하고 있다면 그 주소값을 반환, 없을 시 String Constant Pool에 넣고 새로운 주소값을 반환합니다.
JIT컴파일러란?
➕ 온더플라이 컴파일이라고도 불리는 JIT 컴파일은 프로그램이 실행되는 동안 바이트코드를 머신이나 다른 형식으로 컴파일하여 바이트코드를 사용하는 프로그램의 성능을 높이는 기술입니다. 짐작할 수 있듯이 JVM은 바이트코드를 실행할 때 JIT 컴파일러를 사용합니다.
바이트코드란?
➕ Java 코드를 중간 바이트코드 (.java 확장자를 가진 파일을 .class 확장자를 가진 파일로)로 변환합니다. 바이트코드는 여러 면에서 기계어 코드와 유사하지만 실제 프로세서가 아닌 가상 프로세서의 명령어 세트를 사용한다는 점만 다릅니다. 또한 프로그램이 실행되는 실제 프로세서에 대한 명령 실행을 최적화하는 JIT 컴파일러 사용에 초점을 맞춘 섹션이 포함될 수 있습니다.
Java의 명명규칙은?
➕ 첫째 대소문자가 구분되며 길이에는 제한이 없습니다.
둘째 예약어를 사용해서는 안됩니다.
셋째 숫자로 시작해서도 안됩니다.
넷째 특수문자는 _, $만 허용됩니다. 또한 여러단어가 합쳐진 경우 첫글자를 제외한 시작글자를 대문자로 구분합니다.
예약어란?
➕
제네릭이란?
➕ 제네릭 타입을 이용해서 컴파일 과정에서 타입 체크를 할 수 있다.
- 제네릭은 클래스와 인터페이스, 메소드를 정의할 때 타입 파라미터로 사용한다.
- 장점
- 컴파일할 때 타입을 체크해서 에러를 사전에 잡을 수 있다.
- 컴파일러가 타입캐스팅을 해주기 때문에 개발자가 편리하다.
- 타입만 다르고 코드의 내용이 대부분 일치할 때, 코드의 재사용성이 좋아진다.
Call by Reference, Call by Value
➕ Call by Reference
- 매개 변수의 원래 주소에 값을 저장하는 방식. 클래스 객체를 인수로 전달한 경우
Call by Value
- 인수로 기본 데이터형을 사용. 주어진 값을 복사하여 처리하는 방식. 메서드 내의 처리 결과는 메서드 밖의 변수에 영향을 미치지 않는다.
불변 객체가 무엇인지 설명하고 대표적인 Java의 예시를 설명해주세요.
➕ 불변 객체는 객체 생성 이후 내부의 상태가 변하지 않는 객체를 말합니다.
- Java에서는 필드가 원시 타입인 경우 final 키워드를 사용해 불변 객체를 만들 수 있고,
- 참조 타입일 경우엔 추가적인 작업이 필요합니다.
참조 타입일 경우 추가적인 작업은 어떤게 있는지 설명해주세요.
- 참조 타입은 대표적으로 1.객체를 참조할 수도 있고, 2.배열이나 3.List 등을 참조할 수 있습니다.
- 참조 변수가 일반 객체인 경우 객체를 사용하는 필드의 참조 변수도 불변 객체로 변경해야 합니다.
- 배열일 경우 배열을 받아 copy해서 저장하고, getter를 clone으로 반환하도록 하면 됩니다.
(배열을 그대로 참조하거나, 반환할 경우 외부에서 내부 값을 변경할 수 있음. 때문에 clone을 반환해 외부에서 값 변경하지 못하게 함)
- 리스트인 경우에도 배열과 마찬가지로 생성시 새로운 List를 만들어 값을 복사하도록 해야 합니다.
배열과 리스트는 내부를 복사하여 전달하는데, 이를 방어적 복사(defensive-copy)라고 합니다.
불변 객체나 final을 굳이 사용해야 하는 이유가 있을까요?
- 불변 객체나 final 키워드를 사용해 얻는 이점은 다음과 같습니다.
- Thread-Safe하여 병렬 프로그래밍에 유용하며, 동기화를 고려하지 않아도 된다.
(공유 자원이 불변이기 때문에 항상 동일한 값을 반환하기 때문)
- 실패 원자적인 메소드를 만들 수 있다.
(어떠한 예외가 발생되더라도 메소드 호출 전의 상태를 유지할 수 있어 예외 발생 전과 똑같은 상태로 다음 로직 처리 가능)
- 부수효과를 피해 오류를 최소화 할 수 있다.
※ 부수효과 : 변수의 값이 바뀌거나 객체의 필드 값을 설정하거나 예외나 오류가 발생하여 실행이 중단되는 현상
- 메소드 호출 시 파라미터 값이 변하지 않는다는 것을 보장할 수 있다.
- 가비지 컬렉션 성능을 높일 수 있다.
(가비지 컬렉터가 스캔하는 객체의 수가 줄기 때문에 Gc 수행 시 지연시간도 줄어든다.)
가변 객체와 불변 객체를 설명해주세요.
가변 객체
- 가변 객체는 Java에서 Class의 인스턴스가 생성된 이후에 내부 상태가 변경 가능한 객체이다. 가변 객체는 멀티 스레드 환경에서 사용하려면 별도의 동기화 처리가 필요합니다.
- 대표적인 가변 객체로 ArrayList, HashMap, StringBuilder, StringBuffer 등이 존재한다.
- 이외에도 프로그래머가 커스텀 객체를 생성하여 내부 상태를 변경할 수 있게 만든다면, 그것도 가변 객체가 된다.
불변 객체
- 불변 객체는 가변 객체와 반대로 Java에서 Class의 인스턴스가 생성된 이후에 내부 상태를 변경할 수 없는 객체이다. 불변 객체는 멀티 스레드 환경에서도 안전하게 사용할 수 있다는 신뢰성을 보장합니다.
- 대표적인 불변 객체로 String 등이 존재한다. 이외에도 프로그래머가 커스텀 객체를 생성하여 내부 상태가 변경되지 않게 만들면, 그것도 불변 객체가 된다.
불변 객체의 장점
- Thread-safe하여 병렬 프로그래밍에 유용하며, 동기화를 고려하지 않아도 된다.
- 실패 원자적인(Failure Atomic) 메소드를 만들 수 있다.
- Cache, Map, Set 등의 요소로 활용하기에 적합하다.
- 부수 효과(Side Effect)를 피해 오류 가능성을 최소화할 수 있다.
- 다른 사람이 작성한 함수를 예측 가능하며 안전하게 사용할 수 있다.
불변 객체를 만드는 방법
- 모든 필드에 대해 final을 설정한다.
- 필드에 참조 타입이 있을 경우, 해당 객체도 불변성을 보장해야 한다.
- 필드에 컬렉션이 존재할 경우, 생성자 및 getter에 대해 방어적 복사를 수행해야 한다.
방어적 복사를 사용하면 항상 불변성을 보장하나요?
그렇지 않다. 방어적 복사는 컬렉션의 요소에 대해 얕은 복사를 수행하므로 컬렉션의 참조 타입이 가변 객체라면, 복사하려는 컬렉션의 요소가 변경될 경우 불변성이 깨진다.
추상 클래스와 인터페이스를 설명해주시고, 차이에 대해 설명해주세요.
➕ 추상 클래스는 클래스 내 추상 메소드가 하나 이상 포함되거나 abstract로 정의된 경우를 말합니다.
- 단일 상속을 지원합니다.
- 변수를 가질 수 있습니다.
- 자식 클래스에서 상속을 통해 abstract 메소드를 구현합니다. (extends)
- 인터페이스는 모든 메소드가 추상 메소드로만 이루어져 있는 것을 말합니다.
- 다중 상속을 지원합니다.
- 변수를 가질 수 없습니다. 상수는 가능합니다.
- 모든 메소드는 선언부만 존재합니다.
- 구현 클래스는 선언된 모든 메소드를 overriding 합니다.
public static final float pi = 3.14F; static final int GAME_LEVEL = 10;
- 공통점
- new 연산자로 인스턴스 생성 불가능
- 사용하기 위해서는 하위 클래스에서 확장/구현 해야 한다.
- 차이점
- 인터페이스는 그 인터페이스를 구현하는 모든 클래스에 대해 특정한 메소드가 반드시 존재하도록 강제함에 있고,
- 추상클래스는 상속받는 클래스들의 공통적인 로직을 추상화 시키고, 기능 확장을 위해 사용된다.
- 추상클래스는 다중상속이 불가능하지만, 인터페이스는 다중상속이 가능하다.
- 다중상속 - 인터페이스(defulat ) , 추상클래스
String, StringBuffer, StringBuilder의 차이를 설명해주세요.
➕ String은 불변의 속성을 가지며, StringBuffer와 StringBuilder는 가변의 속성을 가집니다.
- StringBuffer는 동기화를 지원하여 멀티 쓰레드 환경에서 주로 사용하며,
- StringBuilder는 동기화를 지원하지 않아 싱글 쓰레드 환경에서 주로 사용합니다.
String 객체가 불변인 이유에 대해 아는대로 설명해주세요.
1. 캐싱 기능에 의한 메모리 절약과 속도 향상
Java에서 String 객체들은 Heap의 String Pool 이라는 공간에 저장되는데, 참조하려는 문자열이 String Pool에 존재하는 경우 새로 생성하지 않고 Pool에 있는 객체를 사용하기 때문에 특정 문자열 값을 재사용하는 빈도가 높을 수록 상당한 성능 향상을 기대할 수 있다.
2. thread-safe
String 객체는 불변이기 때문에 여러 쓰레드에서 동시에 특정 String 객체를 참조하더라도 안전하다.
3. 보안기능
중요한 데이터를 문자열로 다루는 경우 강제로 해당 참조에 대한 문자열 값을 바꾸는 것이 불가능하기 때문에 보안에 유리하다.
String, StringBuffer, StringBuilder의 차이와 장단점 상세히 말씀해주세요.
Java에서 문자열을 다루는 대표적인 클래스로 String, StringBuffer, StringBuilder가 있다.
알아보기에 앞서 이 클래스들의 공통점은 모두 다 String(문자열)을 저장하고 관리하는 클래스들이 라는 것이다.
연산이 많지 않을때는 위에 나열된 어떤 클래스를 사용하더라도 이슈가 발생할 가능성은 거의 없다.
그러나 연산횟수가 많아지거나 멀티쓰레드, Race condition 등의 상황이 자주 발생한다면,
각 클래스의 특징을 이해하고 상황에 맞는 적절한 클래스를 사용해야 할 것이다.
1. String vs StringBuffer / StringBuilder
String과 StringBuffer/StringBuilder 클래스의 가장 큰 차이점은 String은 불변(immutable)의 속성을 갖는다는 점이다.
아래의예제에서 "hello" 값을 가지고 있던 String 클래스의 참조변수 str이 가리키는 곳에 저장된 "hello"에 "world" 문자열을 더해 "hello world"로 변경한 것으로 착각할 수 있다.
String str = "hello";// String str = new String("hello");
str = str + "world";// [ hello world ]하지만 기존에 "hello"값이 들어가있던 str이 "hello world"라는 값을 가지고 있는 새로운 메모리영역을 가리키게 변경되고,
처음 선언했던 "hello"로 값이 할당 되어 있던 메모리 영역은 Garbage로 남아있다가 GC(garbage collection)에 의해 사라지게 된다.
String 클래스는 불변하기 때문에 문자열을 수정하는 시점에 새로운 String 인스턴스가 생성된 것이다.
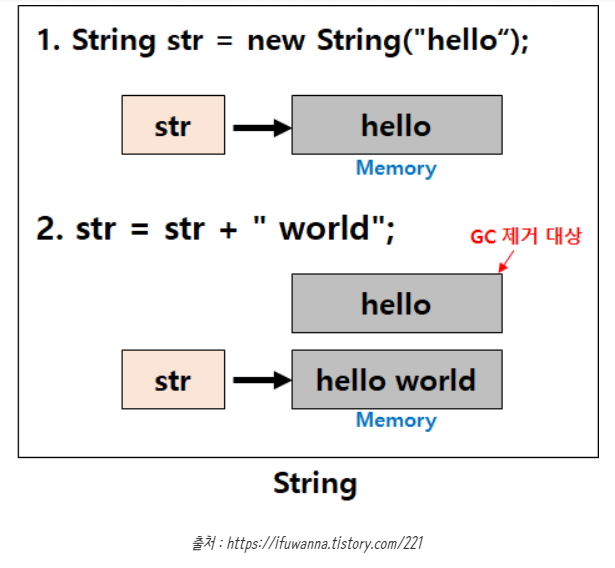
위와 같이 String은 불변성을 가지기 때문에 변하지 않는 문자열을 자주 읽어들일 경우 String을 사용하면 좋은 성능을 발휘한다.
그러나 문자열 추가, 수정, 삭제 등의 연산이 빈번하게 발생하는 경우에 String 클래스를 사용하면 힙 메모리(Heap)에 많은 Garbage가 생성되어 힙 메모리 부족으로 성능에 치명적인 영향을 끼친다.
2. 이를 해결하기 위해 Java에서는 가변(mutable)성을 가지는 StringBuffer / StringBuilder 클래스를 도입했다.
String 과는 반대로 StringBuffer / StringBuilder 는 가변성을 가지기 때문에 .append( ) .delete( ) 등의 API를 이용하여
동일 객체 내에서 문자열을 변경하는 것이 가능하다. 따라서 문자열의 추가, 수정, 삭제가 빈번하게 발생할 경우라면
String 클래스가 아닌 StringBuffer / StringBuilder를 사용해야 한다.
StringBuffer sb = new StringBuffer("hello");
sb.append("world");
3. StringBuffer vs StringBuilder
동일한 API를 가지고 있는 StringBuffer 와 StringBuilder의 차이점은 무엇일까?
가장 큰 차이점은 동기화의 유무로써 StringBuffer는 동기화 키워드를 지원하여 멀티쓰레드 환경에서 안전(thread-safe)하다.
참고로 String도 불변성을 가지기 때문에 마찬가지로 멀티쓰레드 환경에서의 안정성(thread-safe)을 가지고 있다.
반대로 StringBuilder는 동기화를 지원하지 않기 때문에 멀티쓰레드 환경에서 사용하는 것은 적합하지 않지만
동기화를 고려하지 않는 만큼 단일쓰레드에서의 성능은 StringBuffer보다 뛰어나다.
4. 결론
단순히 성능만 놓고 본다면 연산이 많은 경우
StringBuilder > StringBuffer >>> String 정도로 보면 된다.
하지만 각 클래스들은 성능 이슈 외에도 사용 편의성, 멀티 스레드 환경 등 여러가지 고려해야할 요인이 있으므로
아래와 같은 경우에 맞게 사용하면 될 것이다.
String : 문자열 연산이 적고 멀티쓰레드 환경일 경우
StringBuffer : 문자열 연산이 많고 멀티쓰레드 환경일 경우
StringBuilder : 문자열 연산이 많고 단일쓰레드이거나 동기화를 고려하지 않아도 되는 경우
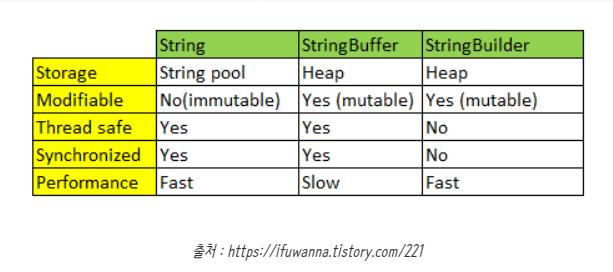
static에 대해 설명해주세요.
➕ static 키워드를 사용한 변수나 메소드는 클래스가 메모리에 올라갈 때 자동으로 생성되며 클래스 로딩이 끝나면 바로 사용할 수 있습니다. 즉, 인스턴스(객체) 생성 없이 바로 사용 가능합니다.
- 모든 객체가 메모리를 공유한다는 특징이 있고, GC 관리 영역 밖에 있기 때문에 프로그램이 종료될 때까지 메모리에 값이 유지된 채로 존재하게 됩니다.
static을 사용하는 이유에 대해 설명해주세요.
- static은 자주 변하지 않는 값이나 공통으로 사용되는 값 같은 공용자원에 대한 접근에 있어서 매번 메모리에 로딩하거나 값을 읽어들이는 것보다 일종의 '전역변수'와 같은 개념을 통해 접근하는 것이 비용도 줄이고 효율을 높일 수 있습니다.
- 인스턴스 생성 없이 바로 사용 가능하기 때문에 프로그램 내에서 공통으로 사용되는 데이터들을 관리할 때 이용합니다.
정적(static)이란?
정적(static)은 고정된이란 의미를 가지고 있다.
static이라는 키워드를 사용하여 static변수와 static메소드를 만들 수 있는 데 다른말로 정적필드와 정적메소드라고도 하며, 이 둘을 합쳐 정적 멤버(= 클래스 멤버)라고 한다.
정적필드와 정적메소드는 객체(인스턴스)에 소속된 멤버가 아니라 클래스에 고정된 멤버이기에 클래스 로더가 클래스를 로딩해서 메소드 메모리 영역에 적재할때 클래스별로 관리된다. 따라서 클래스의 로딩이 끝나는 즉시 바로 사용할 수 있다.
- 객체 생성을 하지 않고 클래스 변수나 메소드를 호출하도록 하는 제어자.
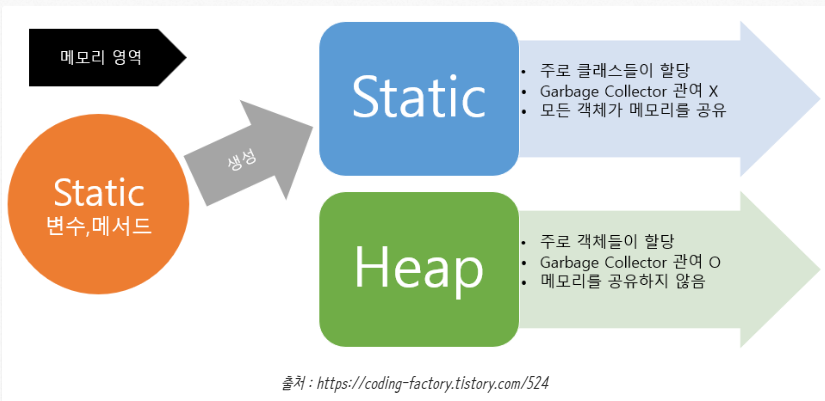
static 키워드를 통해 생성된 정적멤버들은 Heap영역이 아닌 Static영역에 할당된다.
Static영역에 할당된 메모리는 모든 객체가 공유하여 하나의 멤버를 어디서든지 참조할 수 있는 장점을 가지지만,
Garbage Collector의 관리 영역 밖에 존재하기 때문에 프로그램이 종료될 때까지 메모리에 값이 유지된 채로 존재하게 된다. 그렇기에 static을 남발하게되면 성능에 악영향을 줄 수 있다.
결론
- 인스턴스에 공통적으로 사용해야하는 것에 static을 붙인다.
- 인스턴스를 생성하면, 각 인스턴스들은 서로 다른 독립적인 메모리를 할당받기 때문에 서로 다른 값을 유지한다.
- 경우에 따라 인스턴스들이 공통적인 값이 유지되어야 하는 경우에는 static을 붙인다.
- static이 붙은 멤버변수는 인스턴스를 생성하지 않아도 사용할 수 있다.
- static이 붙은 멤버변수(클래스변수)는 클래스가 메모리에 올라갈 때 이미 자동적으로 생성되기 때문이다.
- static이 붙은 메소드(함수)에선 인스턴스 변수를 사용할 수 없다.
- static메소드는 인스턴스 생성 없이 호출 가능한 반면, 인스턴스 변수는 인스턴스를 생성해야만 존재하기 때문에 static이 붙은 메소드를 호출할 때 인스턴스가 생성되어 있을 수도 아닐 수도 있기 때문에 static이 붙은 메소드에서 인스턴스 변수의 사용을 허용하지 않는다.
- 반대로, 인스턴스변수·메소드에선 static이 붙은 멤버들을 사용하는 것은 가능(인스턴스변수가 존재한다는 것은 static 멤버들은 이미 메모리에 존재한다는 것을 의미하기 때문)
- 메소드 내에서 인스턴스 변수를 사용하지 않는다면, static을 붙이는 것을 고려한다.
- 메소드 호출시간이 짧아지기 때문에 효율이 높아진다.
- 클래스 설계시 static의 사용지침
- 클래스의 멤버변수중 모든 인스턴스에 공통된 값을 유지해야하는 것이 있는지 보고 있다면 static을 붙여준다.
- 작성한 메소드 중 인스턴스 변수를 사용하지 않는 메소드에 대해서 static을 붙일 것을 고려한다.
일반적으로 인스턴스변수와 관련된 작업을 하는 메소드는 인스턴스메소드 (static X)이고,
static변수(클래스변수)와 관련된 작업을 하는 메소드는 클래스메소드 (static O)이다.
다음 면접 질문 리스트 보기
https://sunro1994.tistory.com/191
[CS면접 및 자바 면접 준비] 자바 기본 및 객체 질문
아직 내용을 수정중입니다. 혹시 출처를 표기해야 하는 부분이 있다면 댓글 부탁드립니다. Java의 특징 ➕ Java는 객체지향 프로그래밍 언어입니다. 기본 자료형을 제외한 모든 요소들이 객체로
sunro1994.tistory.com
'면접 준비' 카테고리의 다른 글
| [CS면접 및 자바 면접 준비] DB 데이터 베이스 면접 정리 - DB의 기 (0) | 2024.03.28 |
|---|---|
| [CS면접 및 자바 면접 준비] Generic 및 쓰레드 면접 질문 정리 (0) | 2024.03.27 |
| [CS면접 및 자바 면접 준비] Network (1) | 2024.03.26 |
| [CS면접 및 자바 면접 준비] 컬렉션 프레임워크 (3) | 2024.03.23 |
| [CS면접 및 자바 면접 준비] 자바 기본 및 객체 질문 (4) | 2024.03.18 |